Figure 1: IPv6 6/4\6 Address Layout
Copyright © 2008 jsd
Executive summary: IPv6 is good for solving the NAT problem (more properly called the NAPT problem). Routine, standard IPv6 routing can take the place of NAPT hackery. The problem is described in section 3 and the solution is set forth in some detail in section 3.5.
In this document, we emphasize “transitional” solutions. That is, we assume the existence of IPv4 connectivity, and try to get by with minimal additional work. We assume you already have at least an elementary understanding of IPv4 networking.
In this section, we assume you already have basic IPv4 connectivity including a globally-valid IPv4 address. (The case where you don’t have a proper IPv4 address is covered in section 2.2.)
If you want to use IPv6, the first order of business is to obtain some valid IPv6 addresses. This is really quite easy. Assuming you have a valid IPv4 address, you can assign yourself an IPv6 address. In fact, you can assign yourself up to 280 IPv6 addresses.
You do not need to grovel to your ISP or to IANA or to anyone else to obtain these addresses; they are already yours. They came “for free” when you obtained your IPv4 address.1
The best procedure is to use addresses of the form shown in figure 1.
The logic here is simple: We are using the address space reserved for 6/4\6 tunneling, using IP protocol 41 as described in reference 1 and reference 2. That means that given a single IPv4 address, we can parlay it into a group of globally valid IPv6 addresses.
Note various tunneling schemes, and their names: What we are calling 6/4\6 tunneling is also called 6to4 tunneling or sometimes stf tunneling. Each tunnel has two endpoints, each of which can be called a gateway.It is OK to call the tunnel endpoint a 6to4 endpoint, but it would be wrong to think of protocol 41 as a 6-to-4 protocol. The name “6to4” is a horrible misnomer. IP protocol 41 does not help you interoperate between one endpoint that wants to speak IPv4 and another that wants to speak IPv6. IP protocol 41 sets up a tunnel, and both ends of the tunnel must be dual-stack machines.
It is much better to think of IP protocol 41 as a “6-to-6 over 4” protocol ... hence the notation 6/4\6. See section 4.4 for the next level of detail on interoperation.
Here’s an additional source of confusion: The thing that we have been calling a tunnel endpoint is sometimes called a tunnel, for instance in the Linux command ip tunnel add ⋯ which brings up a tunnel endpoint ... which could be associated with zero, one, or many actual tunnels.
Another fine point of terminology: Some people carefully distinguish 6to4 from 6in4, as follows: The name 6in4 applies narrowly to IP protocol 41. Meanwhile, the name 6to4 applies to the combination of 6in4, plus the addressing scheme shown in figure 1, plus the system of relays described in section 4.3.
The name 6over4 applies to a different approach to solving similar problems. It uses an encapsulation scheme different from IP protocol 41, and uses an addressing scheme different from figure 1. It does not interoperate with 6to4. It is not very widely supported, and will not be mentioned again here.
Another scheme for encapsulating IPv6 and pushing it through NAT boxes is Freenet6. See reference 3.
The IPv6 prefix 2002::/16 is reserved for 6/4\6 tunneling, in which case the prefix is followed by the 32-bit IPv4 address of the endpoint. The address layout is shown in figure 1. Reference 1 refers to these as 2002:V4ADDR::/48 addresses.
That leaves at least 80 low-order bits available. It is traditional (but not really mandatory) to divide this into a 16-bit “subnet” field and a 64-bit “endpoint” field. This means you can create thousands of subnets “behind” the gateway, with millions upon millions of hosts per subnet, all with addresses of this form.
Note that you don’t always need to implement any 6/4\6 tunnels, or any kind of encapsulation. For internal use, once you have the addresses, you can, if you want, “forget” to implement the gateway, “forget” about IP protocol 41, and just route the 2002::/16 addresses around your internal networks.
If you have only one subnet, you can set the subnet field to zero and forget about it.
As for the endpoint identifier field, the recommended procedure is to convert the MAC to an EUI-64 as described in the standard, reference 4.
For example, suppose the MAC address is 00:60:1D:22:5A:85. Then the hostname can be set to mybox-0060-1d22-5a85 and the IPv6 address can be set to 2002:a00::260:1dff:fe22:5a85. That address conforms to the EUI-64 standard, which calls for inserting the two bytes ff:fe in the middle, and complementing the 2’s bit in the leftmost byte to indicate that the address is local as opposed to global. Section 6 discusses some scripts that know how to figure out the relevant addresses, set up 6/4\6 tunnels, and update your DNS entries accordingly.
This is considered an “auto configuration” scheme. Technically it does not quite qualify as a “zero configuration” address assignment scheme, because it assumes somebody has already assigned an IPv4 address to the NAPT box. But it’s close to zero configuration. That is, if you have N boxes, the amount of fussing you need to do is not proportional to N.
Technically, you don’t need to use the EUI-64 as the endpoint identifier. If you are in a hurry, with no tools available, you could just assign arbitrary numbers (1, 2, 3 or whatever) to the various interfaces in your network. You just have to be careful to make them unique across your network, or at least unique across each subnet. However, tools such as the scripts discussed in section 6 make it so easy to use the EUI-64 that there is rarely any advantage in doing anything else.
Often people need to make up some IPv6 addresses on the spur of the moment. So the question arises, does IPv6 provide for private addresses? We expect that it should, in analogy to the way IPv4 provides addresses such as 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16, as described in reference 5.
An all-too-common – but not very good – answer calls for using the IPv6 link-local addresses, namely the ones starting with the fe80 prefix. Alas, that has several problems.
So, we need to overcome these problems. We need addresses that can be routed from subnet to subnet within your organization, and the addresses ought to work with ordinary applications including ping and ftp.
You can create your own extemporaneous organization-wide addresses as follows: Suppose you have three hosts and you want to create an “island” of IPv6 connectivity, perhaps for temporary testing, or perhaps for long-term private use. You can configure them by hand if you want. There are many equally-good ways of doing it. One way is to use the 2002::/16 address block as discussed in section 2.
If you don’t have a valid IPv4 address to use for this purpose, you can instead use a private address such as 10.0.0.0. This reduces things to the problem previously solved in section 2.
Now that you have a few hosts speaking IPv6 ot each other on a LAN link, i.e. on a single piece of ether, the next step is to be able to talk to far-away hosts, via the WAN, which requires routing packets from one link to another.
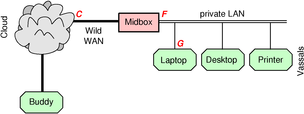
A typical situation is shown in figure 2. You have a number of machines, including a desktop, a laptop, and a networked printer, all hooked up to your private LAN. These machines are called vassals of the midbox, because they are dependent on and subservient to the midbox.
Here’s the objective: We want your buddy, who is attached to the network somewhere far away, to be able to initiate contact to any service on any of the machines on your private LAN.
For now let’s assume the private LAN is inside your home or office, so that all the vassals on your LAN trust each other. (A slightly different scenario, where the machines don’t trust each other, as in a hotel or in a coffee shop, will be discussed later.)
The objective mentioned in section 3.1 is not easily achieved within the IPv4 world. (There is however a nice non-IPv4 solution. Readers who are impatient to see the solution can skip to section 3.5.)
A major problem here has to do with obtaining enough IP addresses to use for all the vassals. There are four billion possible IP addresses, which exceeds the number of computers in the world, but the addresses are not very evenly distributed. You can pretty much assume that your ISP is going to charge you extra if you want more than one IP address.
The conventional pseudo-solution to the IP address shortage is to use NAT (network address translation) which should more properly be called NAPT (network address and port translation).
There are several different things that go by the name “NAT”. The netfilter (iptables) system on Linux makes a useful distiction between MASQUERADE, DNAT, and SNAT ... but these distinctions do not concern us at the moment. MASQUERADE, DNAT, and SNAT are all lumped together under the general rubric of NAT. Again, the name NAPT is more correct and more descriptive, although NAT is more common.
Part of the reason for the so-called IP address shortage is that ISPs often implement PPP in such a way that it uses a block of four addresses per customer, of which only one address is usable by the customer. There is no good reason for this; by way of contrast, cable operators generally only consume on the order of one IP address per customer. Just to add injury to insult, the ISP requires NAPT on every PPP connection (unless you pay extra) because they don’t want to “waste” two more globally-routable IP addresses at points D and E in figure 3.
NAPT is performed in many places in the network. In particular, the midbox shown figure 2 has heretofore, in typical cases, needed to perform NAPT. Midbox is a generic term. In the world today, specific examples of midboxes include things like:
There are so many problems with NAT (aka NAPT) that one hardly knows where to begin the discussion.
At the next level of detail, the reason this problem arises is that NAPT boxes will not hairpin the traffic. That is, they will not perform NAPT on traffic coming in on the private interface, and then send it back out the same interface. They only perform NAPT on traffic coming in one interface and out the other. In some cases it “should” be possible in principle for the NAPT boxes to hairpin the traffic, but in practice they don’t. Maybe some of them do ... but the fact remains that the vast majority of servers behind NAPT boxes cannot have consistent addresses.
Not knowing the DHCP lease time (and similar details) causes problems for the endpoint. You would like to able to anticipate lease expiration, so that you know when to migrate your connections to the new address.
For example, a typical DNS lookup involves one UDP packet inbound and one UDP packet outbound. The whole process sometimes takes a minute or two, but usually takes only milliseconds. Alas, the NAPT box has no way of knowing if/when the process is over, so it needs to keep all UDP-related NAPT table entries alive for a few minutes, at least. Therefore, a NAPT box in front of a busy DNS server might well be burdened with several thousand times more NAPT table entries than are really necessary.
While we’re on the subject, here’s another horror story involving a Cisco 678 DSL modem/router: It does a fine job on ordinary connections initiated from the LAN side, but not on connections initiated from the WAN side. Such traffic requires port-forwarding on the way in, and the replies require NAPT on the way back out. Even under very light load, the router reproducibly loses its mind. I have seen a situation where an existing TCP connection was reproducibly knocked out by a small amount of additional inbound traffic.
Note that I don’t mean to pick on Cisco. It’s just that I have more experience with Cisco modem/routers.
Note that it is not uncommon for packets to be NAPTed more than once. This is discussed in section 3.3.
NAPT does a tolerable job on services that are basic and simple – provided they are initiated from the LAN side of the NAPT box.
In this section, we discuss in some detail a fairly typical situation. This arrangement is not recommended going forward; a better solution is discussed in section 3.5.
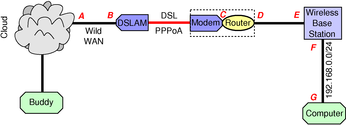
We start by noting that when you buy a so-called DSL modem, the product actually contains both a modem and a primitive router bundled together, as shown by the dotted line in figure 3.
Your ISP probably wants the modem to run PPPoA (PPP over ATM) on the DSL link, for reasons (not very good reasons) discussed in section 3.4.
In this scenario, the ISP assigns you a legit globally-routable IP address on the WAN side of the router, at point C in figure 3. This serves as “the” IP address associated with your service. It is the only globally-routable address they are going to give you (unless you pay extra). In the scripts presented in section 6, this address is represented by the variable WANip4.
Meanwhile, on the LAN side of the DSL router (point D), the router assigns itself a private (non-global) address, say 10.0.0.1 for example. It then offers DHCP on the 10.0.0.0/24 subnet. The WAN side of your wireless base station (point E) picks up an address via DHCP, say 10.0.0.2 for example.
On the LAN side of your wireless base station (point F), it assigns itself a private (non-global) address, say 192.168.0.1 for example. It then offers DHCP on the 192.168.0.0/24 subnet. Your computer picks up an address on this subnet, say 192.168.0.2 for example.
A packet sent from your computer to your buddy gets NAPTed twice at your end (first by your wireless base station, and then again by your DSL router). As a result, your buddy sees WANip4 as the source address of your packet. That makes sense, because it means he sees a globally-routable source address that he can reply to. The reply packet gets NAPTed twice on your end (once by your DSL router and then again by your wireless base station) before reaching your computer.
As an alternative to PPPoA, it is possible to configure a DSL modem-pair to operate in “transparent bridge” mode. That means that rather than implementing a layer-3 connection, the modem-pair implements a layer-2 connection. (Remember that IP is a layer-3 protocol, whereas ether is a layer-2 protocol.) In transparent bridge mode, point A (router at the edge of the cloud) can send IP packets in one hop directly to point E in figure 3, and point E can send IP packets in one hop directly to point A. The globally-routable address assigned to you will be the interface address at point E.
In typical set-ups, transparent bridge mode reduces by one the number of times your traffic gets NAPTed, when compared to PPPoA.
PPP is a holdover from the days of 56K dial-up modems.
If you have a DSL line, PPPoA might be tolerable if all you are doing is web-surfing and other activities where connections are originated from the LAN side.
On the other hand, if you are ever going to do anything where connections are originated from the WAN side, such as receiving VOIP phone calls, or operating any kind of server, you should ask your ISP for transparent bridge mode instead of PPPoA. Technically, PPP isn’t the main problem, but PPP usually brings in a layer of NAT, and NAT is definitely a problem, for all the reasons listed in section 3.2.
Your DSL ISP may try to talk you out of using transparent bridge mode. I’ve listened to the reasons that ISPs give for preferring PPPoA, and I find them to be very weak reasons. PPPoA does give the ISP more information about the state of the connection ... but only slightly more. I’ve never had an ISP tell me anything about the connection that I did not already know from using mtr (a nice traceroute-like utility) and from looking at the modem status pages.
Note that unlike DSL providers, cable providers are happy to have their cable modems operate in transparent bridge mode. They don’t fool with PPPoA.
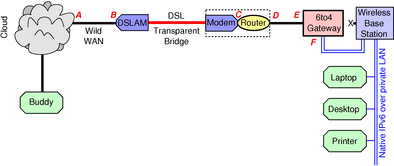
The objective set forth in section 3.1 can be solved using IPv6. The solution is reasonably straightforward, using ordinary network resources as they exist today. It does not require any of your machines to be attached to the IPv6 internet. All it requires is a smart midbox. This idea has been around for years; see e.g. reference 7.
A typical layout is shown in figure 4.
Here are the main elements of the solution:
Note that configuring the tunnel endpoint on your gateway requires knowing WANip4, i.e. the globally-routable IPv4 address assigned to you. It is not always trivial for your gateway to know this. If you are behind a NAPT box, as in figure 4, looking at the address of the gateway’s WAN-side interface (point E) will not tell you what you need to know.
There is no standard way to ask the modem/router (point D) what the WANip4 address is. And for that matter, it might not even know the correct address, if it is behind yet another NAPT box.
The best way to proceed is to determine the WANip4 address empirically. This can be done by contacting some site on the internet, some site that will ascertain your IP address (by looking at the source address of your packets) and tell you what it is. The scripts discussed in section 6 will do this for you.
A useful trick is shown in figure 4: The gateway is connected to the LAN side of the wireless base station. This avoids a worse-than-useless layer of NAPT processing. Leave the WAN port on the wireless base station disconnected, as shown by the X in the figure. Turn off the DHCP server features on the LAN side of the wireless base station, and let the gateway perform the DHCP server function (if this function is needed at all).
Write down the IP address used for configuring the base station. Write this in permanent ink on the base station itself. With DHCP turned off, it might not be easy to figure out this address if/when it is needed later.
To acquire its IPV6 address, a vassal does not need to run anything comparable to a DHCP client daemon; the ability to respond to router advertisements is built into the IPv6 stack.
Having this built-in is a mixed blessing. Downsides include:
The
When configuring radvd, you should uphold the principle that different interfaces should serve different blocks of addresses. In this case, that means your 6to4 tunnel device should have a different subnet number from the device that serves the private LAN segment. The subnet number goes in the SLA-ID field, i.e. the bottom 16 bits of the top 64 bits of the IPv6 address, as shown in figure 1. (I use the kernel’s mapping from adevice names to small integers, as reported by the ip addr ls command. See the conf-6-gw script in section 6.
A device such as a network printer probably wouldn’t derive much benefit from having an IPv4 address.
Remember that the A record should contain WANip4 address, which oftentimes is not the address on the WAN-side interface of the gateway machine (point E in figure 4), as discussed in item 2.
In any case, an A record may not be necessary for present purposes, since your buddy can figure out your assigned global IPv4 address by looking at the bottom 32 of the top 48 bits of the gateway’s IPv6 address, as shown in figure 1.
You can understand this as follows: The NAPT boxes rewrite the packets, but at this point the traffic is encapsulated. The IPv4 envelopes get damaged, but the IPv6 traffic is safely inside the envelope and does not get damaged. At the end of the tunnel, the envelope is thrown away, and undamaged IPv6 traffic proceeds on its way.
If there is NAPTing going on, the main requirement is that each of the NAPT boxes be configured so that it forwards IP protocol 41 (IPv6 encapsulated in IPv4).
(That’s IP protocol 41, not TCP port 41 or UDP port 41. It’s a protocol, not a port. Port-forwarding will not suffice. Protocol-forwarding is required.)
In many cases, using 6/4\6 tunnels even overcomes the UDP/NAT table overflow problem discussed in problem P8. That’s because protocol forwarding does not need to be tabulated. Every packet that needs to be protocol-forwarded gets treated the same way, not requiring any guessing as to which flow it belongs to.
I’ve seen cases where ssh -4 was failing miserably due to NAT-table problems, while ssh -6 was working fine.
Also, on the gateway, you need to configure your IPv4 firewall to permit protocol 41 on the WAN-side interface, incoming and outgoing.
Interoperation with hosts on the IPv6 internet was not one of our objectives. However, if you wish, you can get interoperation almost for free, via relays, as discussed in section 4.3.
The topic of IPv4/IPv6 interoperation covers a lot of ground. We need to be more specific. Factors to be considered include:
For present purposes, it is useful to divide the IPv6 world as follows:
As an initial example, suppose you live in Micronesia and you want to connect to someone somewhere else in Micronesia. This is easy. This is exactly what IP protocol 41 was designed to do.
Protocol 41 deals primarily with the transport issue. It allows two machines to speak IPv6 to each other, even though the network that connects them is IPv4-only. In its simplest form, it assumes that both endpoints are running an implementation of the 6/4\6 encapsulation protocol (which implies that both endpoints are dual-stack). In the slightly fancier form, you can have an IPv6-only endpoint behind a gateway that performs the encapsulation.
If you are in Micronesia somewhere, and you want to connect to Gondwanaland, it won’t happen by magic. There needs to be a relay somewhere. In one direction, the process works as follows: You encapsulate your IPv6 traffic and put the envelopes on the IPv4 network. The relay receives this traffic, decapsulates it, and puts it onto the IPv6 internet as native IPv6. In the other direction, it takes native IPv6 traffic from the IPv6 internet, encapsulates it, and sends it on its way via the IPv4 network.
Such relays exist, so a machine that sits on the IPv4 network and implements 6/4\6 tunneling can in fact interoperate with machines on the IPv6 internet.
These relays have several special properties. For starters, they are connected both to the IPv6 internet and to the IPv4 internet. Secondly, they implement 6/4\6 encapsulation/decapsulation. Thirdly, they choose to offer this as a service to the world.
Our only remaining task is to locate a suitable relay, and route traffic to it. There is a very easy way to do this, because all the world’s routers are supposed to recognize 192.88.99.1 as an anycast address denoting the “nearest” 6/4\6 relay. This is documented in reference 8. So the remaining task is a one-liner: all you need to do is add a line to your routing table that routes IPv6 traffic via that anycast address. The 6to4 script in section 6 does this.
To demonstrate this feature, you can use ping6 to check on the various IPv6 internet hosts mentioned in section 8.1.
Suppose you live somewhere in Gondwanaland, or somewhere in Micronesia, and you want to talk to one of the fish in the sea.
This will not happen by magic. And it will not happen by IP protocol 41. That’s not what protocol 41 was designed to do, and it’s not what it does.
There is no reason why this couldn’t be done, at least partially, but apparently it isn’t (yet?) done to any great extent. I don’t know how to get Linux to do it.
This task is basically a form of NAPT, in particular a form of MASQUERADE, as we now discuss: Suppose that one of the vassals in figure 4 is an IPv6-only machine. If it wants to talk to a machine somewhere on the IPv4 network, it can utter an IPv6 address of the form 0::wwxx:yyzz. The gateway receives this as a native IPv6 packet, but cannot simply forward it, because (a) the network probably wouldn’t carry it, and (b) the IPv4 host at ww.xx.yy.zz wouldn’t understand it anyway. So the gateway “should” transform the packet to an IPv4 packet before sending it on its way.
The replies need to be transformed from IPv4 to IPv6. The gateway needs to keep a table (a typical MASQUERADE table) so that it can recognize the incoming IPv4 packets and know which port on which vassal should receive the packet.
There is not much need for this notion of IPv6 masquerading as IPv4. It doesn’t solve any problems. It has all the same problems as plain old IPv4 masquerading as IPv4, as discussed in section 3.2. Therefore it is simpler to assign an IPv4 address to each vassal, so that the traffic starts out as IPv4 and remains IPv4.
In the forward direction, Domain Name Service is easy. Options include:
You especially need nsupdate or something like it if you have a dynamic IP address. If you are not administering your own nameservers, perhaps the administrator will give you a key so that you can update your own records.
If you have a native IPv6 address, the ISP who provides the address presumably controls the reverse DNS. Any decent ISP will provide a way for you to set up the rDNS records however you like.
If you are using a 2002:V4ADDR::/48 address, i.e. if you are a gateway or a vassal that depends on 6/4\6 tunneling, there is a simple way of setting up rDNS records ... provided you operate your own DNS servers.
On the appropriate servers, set up a reverse zone file covering your 2002:V4ADDR::/48 subnet. Within that file, set up records specifying the names that go with the IPv6 addresses of your hosts. Test this using dig @myserver.whatever -x my:ipv6::address.
Here is an example of a working zone file. The $ORIGIN encodes the 48-bit prefix of your 2002:V4ADDR::/48 subnet. The individual host entries are 80 bits long. The entries use “exploded” format, nibbles separated by dots. Each nibble is one hex digit, representing four bits. As is usual in reverse zone files, the least-significant nibble is on the left. For example, you can see the “2002” prefix on the right of the $ORIGIN.
$ORIGIN 8.9.b.f.7.e.4.4.2.0.0.2.ip6.arpa.
$TTL 86400 ; 1 day
@ IN SOA east-net.example.net. netmaster.example.com. (
2012035273 ; serial
28800 ; refresh (8 hours)
14400 ; retry (4 hours)
3600000 ; expire (5 weeks 6 days 16 hours)
86400 ; minimum (1 day)
)
NS east-net.example.net.
0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0 PTR east-net.example.net.
2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0 PTR address-two.example.net.
0.5.b.4.2.e.e.f.f.f.1.2.2.4.2.0.3.0.0.0 PTR fred.example.net.
9.6.c.8.b.6.e.f.f.f.6.1.a.2.2.0.4.0.0.0 PTR wilma.example.net.
Then in your /etc/bind/named.conf.local file, you will need to tell it about the aformentioned reverse zone file. The string in quotes is the same as the $ORIGIN mentioned above.
zone "8.9.b.f.7.e.4.4.2.0.0.2.ip6.arpa." IN {
type master;
file "rev/east-net_ipv6";
allow-update { key ___.east-net.example.net.; };
};
Once the name servers are working, go to http://6to4.nro.net/ and fill in the form. As far as I can tell, this is not very secure. Apparently if the request comes from anywhere within a given 2002:V4ADDR::/48 subnet, the request to assign or re-assign rDNS servers will be granted. In multi-user environment, this could get ugly.
Note: This works even if you don’t control the reverse-DNS records of the IPv4 address that forms the V4ADDR part of your 2002:V4ADDR::/48 address. It works even if the IPv4 address is dynamically assigned ... although you will have to notice whenever the IPv4 address changes, and set up new rDNS records accordingly.
The first step is to create scripts that make it easy to bring up the IPv6 features, including 6/4\6 tunnel, the Router Advertisement daemon, and so forth. This has been pretty much accomplished. See section 6. Not much skill is required. No hard decisions are required.
The next step is to integrate this with the rest of the system integration process, so that it happens automatically.
Figure 5 lists some of the things that need to happen on the server, and shows some of the dependencies among them. The rule is that each item depends on things that are shown to the left and not below.
For example, the mini-firewall must start before the interfaces come up, and the main firewall must start after they come up. Ascertaining the WANip4 address requires being able to send and receive network traffic, which is not allowed until after the firewall has started.
You can’t configure the 6to4 xunnel2 (which talks to the WAN interface) until you have the WANip4 address. Similarly you can’t configure the IPv6 properties of the LAN interface until you know the WANip4 address. You can’t start advertising the route to the vassals on the LAN until there actually is a route (configured by 6to4), and the LAN interface has been fully configured (by conf-6-gw) and there is a suitable radvd.conf file (written by conf-6-gw).
You can’t update your DNS records until you know WANip4 and until the DNS server is up.
At system boot time, it is satisfactory to wait until the local DNS server (if any) is up, and then do all the IPv6-related stuff in one swell foop.
In contrast, things are much trickier if the WANip4 changes while the system is running. We need to re-initialze the tunnel, re-assign all the IPv6 addresses on the LAN, change the routes, and then notify all the DNS servers about the new gateway and vassal addresses. The event-based approach that is gradually being phased in to recent Debian versions seems like the right way to go, but the setup scripts (below) do not take this approach.
Similarly things get tricky if one of the DNS servers is down at the time we want to update it; there is not yet any provision for automatic retries.
Here is an overview of the configuration scripts. They are in a pre-alpha or early-alpha state.
Meanwhile, on each vassal, you need to invoke update-ns sometime after a router advertisement has been accepted. For now, you need to do this by hand; there is not yet any provision for making it happen automatically. It seems we should move away from the old-style init.d/script approach toward an event-driven approach, but I haven’t (yet?) implemented that. For now a check-wait-check-wait loop is all that is available. Suggestions for better ways to do this would be welcome.
All of these scripts need work; in particular they need to be more defensive about user errors, such as calling 6to4 on a box that doesn’t need a tun, because it already has been given a working IPv6 address.
Executive summary: IPv6 was designed to include hooks to facilitate IPsec. On Linux, this works fine.
For me, getting IPsec to work on IPv6 was almost trivial. The nexthop issue slowed me down for a few minutes; see section 7.2.
Another possibly-useful observation: The manpage for ipsec.conf makes the important point that the two ends of an IPsec connection do not need to agree about the other guy’s "nexthop" address. Let me take that one step further: They don’t even need to agree on whether there is a nexthop. This is important, because the 6to4 tunneling device, and probably a lot of other tunneling devices, are for practical purposes NBMA devices (non-broadcast multiple access). That means they don’t need to do ARP, and couldn’t do ARP if they wanted to ... there is no need for IPsec to worry about the nexthop for such devices. To put an even finer point on it, the 6to4 tunneling device makes all connections appear local; "ip route get to ..." reports a nexthop ("via") address, but it is always the same as the local interface address. So if you are routing IPsec into a 6to4 device, you should specify no nexthop address (neither for the right side nor the left side). In the scenario in the following diagram, east needs to specify a nexthop while west needs to specify no nexthop.
west ----------- midbox ============= east
6/4\6 native
tunnel IPv6
As always, when specifying a nexthop, leftnexthop needs to be correct, while rightnexthop can be completely bogus, or can be omitted entirely. (Note that in my world, "left" is always "local", and "right" is always "remote".) I always omit rightnexthop.
The only reason why rightnexthop would ever be useful is if you are planning to use the "alsoflip" directive. That’s of no importance on my systems, because I’ve never been tempted to use "alsoflip" anyway. I have scripts that generate all my .conf files, so there is never any need to flip anything.
Here is an example of a .conf file, taken from a simple but realistic case. (A more sophisticated example can be found in section 7.4.)
conn sunset_24_east
## Automatically created by mk_conf
## so you probably don't want to be editing this.
auto="add"
keyingtries="0"
connaddrfamily="ipv6"
##
leftid="@sunset.example.net"
left="2002:4a6b:e723:3:205:4eff:fe4b:c8cf"
leftrsasigkey="0sAQNM....hIp"
leftnexthop="fe80::201:2ff:fe29:564d"
##
rightid="east.example.net"
right="2002:4387:d370::"
rightrsasigkey="0sAQP....LMsP"
Here are some nice things I’ve noticed about the NETKEY IPsec stack that is built into the Linux kernel:
I think interfaces=%none should be made the default when KLIPS is not being used. At the very least, the freedom to choose interfaces=%none should be documented.
Here are some not-so-nice things I’ve noticed about the NETKEY IPsec stack:
You can work around this, so that you can see the encrypted data fresh off the wire, by defining an alias device (e.g. eth0:1) with a different address, and applying tcpdump to that.
At the next level of detail: You may find the following commands useful.
ping6 otherguy.example.net -p feedfacedeadbeef tcpdump -nexli eth0
The -p option to ping specifies an easily-recognizable payload pattern, and the -x option to tcpdump causes enough of the packet to be dumped so that you can see whether the pattern appears in the clear or not. Be sure to run the tcpdump command on the originating end (where the ping command is running) and also on the other end.
By way of motivation, let us take note of the fact that sometimes even when there is an IPsec connection between one host and another, you may want to bypass that connection. For example, if you trust ssh to be secure, it is not necessary to layer ssh on top of IPsec. This sort of bypass comes in very handy if you need to debug or reconfigure the IPsec connection.
There is an elegant way of making this work.
To see how this works, consider the scenario shown in the following diagram, where there is an IPsec connection between West and East (and no other IPsec connections):
(a) (b) (c) (d) (g) (h) (i) (j)
Sunset-2 ============= West ----- cloud ----- East ============= Sunrise-2
sunset-net sunrise-net
There are many modes in which IPsec can operate. These include
Many people ignore transport mode entirely. There is not much (if anything) that you can do with transport mode that you cannot do with a host-to-host tunnel.
Carrying that idea to the next level, I recommend ignoring everything except subnet-to-subnet tunnel mode. One advantage is that in subnet to subnet mode, West has two addresses [(c) and (d)], and similarly East has two addresses [(g) and (h)]. Since the IPsec tunnel runs from subnet to subnet, traffic addressed to/from (c) from/to (h) will flow through the IPsec tunnel. In contrast, traffic addressed to/from (d) from/to (g) will be ignored by the IPsec system, and will flow in the clear.
Let us now consider some degenerate cases. We start with the case where sunrise-net does not exist, meaning that East is just a plain host, i.e. an endpoint, not serving as a gateway to any subnet. You can still use IPsec in subnet-to-subnet mode, simply by creating a dummy subnet, using the dummy0 network device. This is extra work compared to using a basic host-to-host tunnel, but only a small amount of extra work, and it is well worth it. Choosing an address is easy if East is connected to the IPv4 network, and therefore has a 6to4 address, because that address has 80 uncommmitted bits we can play with. I recommend that the address on the dummy interface at point (h) be formed from the 6to4 address at point (g) by setting the 0:0:0:8000:: bit, that is, the highest-order bit in the “SLA ID” field as defined in figure 1. Examples of this can be seen in the configuration example below. Because there are so many low-order bits to play with, the dummy subnet can have many members if you want ... but it doesn’t really need more than one member.
A tricker case concerns the Sunset-2 host, which is not directly connected to the IPv4 network. It has an IPv6 address, which it was able to autoconfigure with the help of the router advertisement daemon running on West. This is a perfectly valid IPv6 address, but it has relatively few bits available for us to play with. The low-order 64 bits were consumed by the autoconfiguration process. Again I recommend forming the subnet address at point (a) by setting the 0:0:0:8000:: bit. In this case, the subnet must have only one member, i.e. it must be a “/128” subnet.
Note that nominally the SLA ID field is dictated by the router advertisement daemon, so to make this addressing scheme work we need some cooperation from the daemon, i.e. the daemon needs to agree to treat the high-order bit in the SLA ID as “reserved”.
Here is a rough checklist for setting up a subnet-to-subnet tunnel:
ifconfig dummy0 add 2002:46ab:e273:8003:205:4eff:fe4b:cc8f/128
ip route add 2002:4387:d370:8000:: src 2002:4a6b:e723:3:205:4eff:fe4b:c8cf dev eth0
The main purpose of this step is to specify the src. (Without this route, you would still be able to send pings through the IPsec tunnel, but you would need to specify the source address each time, using the -I argument to ping.)
Here is an example of the “conn” declaration for a subnet-to-subnet tunnel, using a dummy subnet on each end:
conn sunset_24_east
## Automatically created by mk_conf
## so you probably don't want to be editing this.
auto="add"
keyingtries="0"
connaddrfamily="ipv6"
##
leftid="@sunset.example.net"
left="2002:4a6b:e723:3:205:4eff:fe4b:c8cf"
leftrsasigkey="0sAQNM....hIp"
leftnexthop="fe80::201:2ff:fe29:564d"
leftsubnet="2002:4a6b:e723:8003:205:4eff:fe4b:c8cf/128"
leftsourceip="2002:4a6b:e723:8003:205:4eff:fe4b:c8cf"
##
rightid="east.example.net"
right="2002:4387:d370::"
rightrsasigkey="0sAQP....LMsP"
rightsubnet="2002:4387:d370:8000::/128"
It is important to design things so that they scale properly.
If you have N hosts fully connected with IPsec tunnels, that requires a total of N2 “conn” declarations, all different. Each host only needs N of these “conn” declarations in its ipsec.conf file, but that doesn’t address the underlying issue: where did all those declarations come from? I don’t want to have a central database containing N2 of anything. That would defeat one of the main raisons d’être of asymmetric cryptography.
Constructive suggestion: It is perfectly possible to keep a central database with only N entries, one for each IPsec endpoint. Indeed, each of the entries is quite simple, recording only the hostname, subnet configuration (if any), and the RSA public key of the endpoint. Here’s an example:
id=@foo.example.net subnet=foo-s.example.net/128 # RSA 2192 bits foo Sat Sep 27 18:16:53 2008 rsasigkey=0sAQP....LMsP
I store that information in a “.pub” file, one file per endpoint.
I have a script that takes two .pub files and creates the “conn” declaration suitable for connecting the two endpoints. Given the information in the .pub files, everything else needed for the “conn” declaration can be figured out by consulting DNS and consulting the routing tables, plus some logic and arithmetic.
An alpha version of the script is at mk_conf . This is a rough draft, but better than nothing.
I would like to see this functionality integrated into openswan. In my opinion, stuff like “interfaces=...” and “leftnexthop=...” do not belong in the ipsec.conf file. And the IPsec packets should be routed according to the actual routes, not the “defaultroute”. Everything that can be figured out at runtime should be figured out at runtime.
Some organizations that have useful IPv6 sites hide them under funny names. For example, www.google.com has A records only while ipv6.google.com has an AAAA record only. In my opinion, this is obnoxious, because it means that you can’t send a Google URL via email to a group of people and expect it to work for IPv6-only hosts as well as IPv4-only hosts. The smart thing for a server to do is to settle on one domain name, give it both an A record and an AAAA record, and let the clients sort out which one they want to use.
As an example, Google offers URLs for ancillary services such as maps and books, but the URLs take you to the IPv4 sites, which is unhelpful if you are on an IPv6-only host. It is possible to kludge around this as follows: Instead of going to maps.google.com/, go to ipv6.google.com/maps. Similarly for ipv6.google.com/books et cetera. In my opinion, this is very inconvenient compared to just clicking on a link that points to the right thing. It defeats the primary raison d’être of the web browser.
On the other hand, to keep this in perspective, bear in mind that google offers some usable IPv6 service, which is more than you can say for most other organizations.
As of 3Q 2008, a surprisingly small fraction of the world’s corporations and universities appear to be accessible via IPv6. That is to say, they are not advertising IPv6 addresses via DNS in any obvious way.
As if that weren’t bad enough, surprisingly many of the organizations that do have AAAA records have broken records. Problems include subdomains with nameservers that don’t respond, CNAMEs that don’t point to anything real, hosts with no route to host, hosts that doesn’t respond to ping or telnet, et cetera.
Back in 2003, the US Department of Defense decided that military networks must move to IPv6 by 2008. I don’t know to what extent this deadline has been met, but I observe that as of 3Q 2008, few if any military sites have IPv6 addresses facing outward toward the public internet. For example, www.army.mil and pentagon.afis.osd.mil appear to be IPv4-only. Maybe the DoD IPv6 is confined to their internal networks.
Some organizations that do have valid AAAA records in their DNS servers are listed in the following table. Also note that you can get an overview of who’s who on the IPv6 internet via reference 9. A brief listing of “Cool IPv6 Stuff” can be found at http://www.sixxs.net/misc/coolstuff/.
a.gtld-servers.net. 0 IN AAAA 2001:503:a83e::2:30 b.gtld-servers.net. 0 IN AAAA 2001:503:231d::2:30 www.apnic.net. 0 IN AAAA 2001:dc0:2001:0:4608:20:: sunic.sunet.se. 0 IN AAAA 2001:6b0:7::2 ns1.nic.uk. 0 IN AAAA 2a01:40:1001:35::2 ns3.nic.fr. 0 IN AAAA 2001:660:3006:1::1:1 rigolo.nic.fr. 0 IN AAAA 2001:660:3003:2::4:20 lacnic.net. 0 IN AAAA 2001:12ff:0:2::15 ns1.dns.net.nz. 0 IN AAAA 2001:dce:2000:2::130 a.dns.jp. 0 IN AAAA 2001:dc4::1 a.dns.cn. 0 IN AAAA 2001:dc7::1 ns1.denic.de. 0 IN AAAA 2001:608:6:6::11 hippo.ru.ac.za. 0 IN AAAA 2001:4200:1010::1 psg.com. 0 IN AAAA 2001:418:1::62 rip.psg.com. 0 IN AAAA 2001:418:1::39 ns-sec.ripe.net. 0 IN AAAA 2001:610:240:0:53::4 www.isoc.org. 0 IN AAAA 2001:4830:2480:11::137 ietf.org. 0 IN AAAA 2001:1890:1112:1::20 icann.org. 0 IN AAAA 2620:0:2d0:1::103 iana.org. 0 IN AAAA 2620:0:2d0:1::193 c.iana-servers.net. 0 IN AAAA 2001:648:2c30::1:10 d.iana-servers.net. 0 IN AAAA 2620:0:2d0:1::44 huponomos.wifi.pps.jussieu.fr. 0 IN AAAA 2001:660:3301:8061:290:27ff:feac:7980 huponomos.wifi.pps.jussieu.fr. 0 IN AAAA 2001:660:3301:8063::1 www6.netbsd.org. 0 IN AAAA 2001:4f8:4:7:2e0:81ff:fe52:9a6b he.net. 0 IN AAAA 2001:470:0:76::2 www.ntt.net. 0 IN AAAA 2001:418:0:7::101 ftp.cw.net. 0 IN AAAA 2001:5000:0:300::15 sprintv6.net. 0 IN AAAA 2001:440:1239:4::2 web.dante.net. 0 IN AAAA 2001:798:2:284d::60 websrvr03.ukerna.ac.uk. 0 IN AAAA 2001:630:1:1:214:4fff:fe0f:baf2 www.renater.fr. 0 IN AAAA 2001:660:3001:4002::10 6to4.kfu.com. 0 IN AAAA 2002:478d:4001::1 future.ipv6.chello.com. 0 IN AAAA 2001:730:0:1:a00:20ff:fec1:b1f0 www.vsix.net. 0 IN AAAA 2001:2b8:1::100 www.potaroo.net. 0 IN AAAA 2001:dc0:2001:7:215:c5ff:fefc:5f07 www.occaid.net. 0 IN AAAA 2001:4830:100:20::6 limekiller.ipv6.mit.edu. 0 IN AAAA 2001:4830:2446:b5::1 www.kame.net. 0 IN AAAA 2001:200:0:8002:203:47ff:fea5:3085 ipv6.l.google.com. 0 IN AAAA 2001:4860:0:2001::68 www.hexago.com. 0 IN AAAA 2001:5c0:0:1::6 www.sunny.ch. 0 IN AAAA 2001:8a8:20::23
Note that 2001::/16 is the range of normal “production” IPv6 addresses, which are assigned top-down. These are not to be confused with the 2002::/16 range that we use for 6/4\6 tunnel addresses. I don’t know the story about the 2620::/16 addresses.
Once you have valid IPv6 addresses on your host(s), and usable transport as discussed in section 8.3, you can put them to use if you have IPv6-aware tools. Here is a rundown of the status of some tools that may be of interest:
http://[2607:f2f8:a8c4::2]:80/computer/
If a given hostname has no A record, only an AAAA record, firefox will use the IPv6 address, as in the following example:
http://ipv6.av8n.com:80/computer
If a given hostname has both an A record and an AAAA record, firefox uses the IPv4 address. If you want to use the IPv6 address and you have control over the host’s DNS records, you can define an alias, i.e. another hostname for the same host, with only an AAAA record, as in the preceding example.
If all you have is a hostname that has both an A record and an AAAA record, I don’t know how to get firefox to use the IPv6 address. (Previously you could just put the hostname in square brackets, but this no longer works.)
Once you have valid IPv6 addresses on your hosts, you need a way for IPv6 packets to get from one host to another.
There are two main ways this can happen, namely native IPv6 or encapsulation, as we now discuss:
This means that if you have a local area network, where everything is connected at layer 2 or below, then native ethernet should work without any fuss. Common layer-1 links that are known to transport native IPv6 include direct ethernet wires and ethernet connected via hubs. Common layer-2 links that are known to transport native IPv6 include ethernet switches, bridges, and 802.11 wireless.
Moving now from layer 2 to layer 3: If you have multiple network segments connected at layer 3, i.e. connected by a router as opposed to hubs or bridges, then IPv6 will propagate across the router if and only if the router was designed to support that. If you are buying generic IP service from a generic ISP, beware that as of 3Q 2008 most ISPs are not able to transport native IPv6. The few ISPs that do offer native IPv6 connectivity are listed at http://www.sixxs.net/faq/connectivity/?faq=native.
In a broader context, IP protocol 41 is called v6 over v4 tunneling. Note that this is definitely not native IPv6. It is analgous to IPIP encapsulation (IP protocol 94). If things were named consistently, protocol 41 would be named IPV6IP, in analogy to IPIP ... but for some reason it is just called IPV6. Do not be confused by the name. In particular, do not confuse IPV6 tunneling (IP protocol 41 layered on ethertype 0x0800) with native IPv6 (ethertype 0x08dd).
Note that unlike, say, IPsec, tunneling IPv6 over IP does not require even the slightest pre-arrangement or coordination between the endpoints. Each host brings up its “half” of the tunnel, and that’s all that’s required ... assuming the hosts have a good IPv4 link, and the link doesn’t block IP protocol 41. In fact, if you have N hosts and each one brings up its 6to4 endpoint, you then have N(N−1)/2 tunnels. That means calling the endpoint a “half tunnel” is a misnomer; it is better to call it a tunnel endpoint, since it can serve as the endpoint for many many tunnels.
See reference 11 for an overview of 6/4\6 tunnels, including a super-simple script for setting up a 6/4\6 tunnel. Section 6 discusses some much fancier scripts that know how to figure out the relevant addresses, set up a 6to4 endpoint, and update your DNS entries accordingly.
Copyright © 2008 jsd