Figure 1: 3He Superfluid Transition Data
Once upon a time in a mythical place called La Jolla there was a fellow named John who really liked numbers. The more digits the better. He wanted unbiased numbers so dearly that he would have his grad student, Richard, face the instrument with his eyes closed. Then every so often John would say “Now!”, whereupon Richard would momentarily open his eyes, observe the instrument, and call out the number. John would write it in the lab book. After doing this for many days and weeks, they had lots of lab books filled with lots of numbers.
They were hoping to see some sign of a superfluid transition in liquid 3He at low temperatures. John had already made a string of important discoveries in low-temperature physics, and finding the superfluid would earn him an all-expense-paid trip to Stockholm.
Aside: The nice thing about theoretical predictions is that there are so many to choose from. Predictions of Tcq started at about 300 milliKelvin. When that was disproved experimentally, the predictions moved to lower temperatures. 100 mK was disproved. 50 mK was disproved. 30 mK was disproved. 10 mK was disproved. In fact John and Richard had checked experimentally down to less than 2.5 mK without seeing anything. So the theorists gave up and lowered their prediction to something in the microKelvin range.
Once upon the same time, in a mythical place called Ithaca, there were a couple of guys named Bob and Doug. They liked numbers OK, but they also liked graphs. They wanted to see the data. And they didn’t want to wait until the experiment was over to analyze the data and see what it meant; they wanted to see the data in real time. This is in the days before computers, so if you wanted a graph you had to suffer for it, fooling with Leeds strip-chart recorders with paper that always jammed and pens that always clogged.
On the last Wednesday in November, Doug was watching the chart as the cell cooled through 2.5 mK. There was a glitch on the T versus t trace. Doug identified it and wrote “Glitch!!” on the chart. He warmed back up and saw it again on the way up. And then again on the way back down. He called Bob. Bob zoomed into the lab. The two of them spent all night and most of Thanksgiving day walking back and forth through the “glitch”.
As you can see in figure 1, it doesn’t look like what I would call a glitch. It’s just a small-angle corner. The change in slope is perceptible, but not enormous. Eyes are good at spotting corners in otherwise-straight lines.
Doug and Bob assumed, based on the aforementioned experimental and theoretical evidence, that this wasn’t the superfluid transition. They figured it was something going on in the nearby solid 3He. But they eventually figured out that it was indeed the superfluid. Right there at 2.5 mK.
Everybody assumes that if John and Richard had been plotting their data on a strip-chart recorder, they would in fact have discovered the superfluid. But they didn’t.
Now, imagine what it was like working in Bob’s lab after that. All the significant variables had strip- chart recorders attached to them. Even variables you were pretty sure weren’t significant had strip-chart recorders attached to them.
Every so often, a new baby grad student, his fingers stained N different colors from trying to unclog the chart pens, would ask whether we really needed all those chart recorders. Somebody would explain by saying, Once upon a time in a mythical place called La Jolla, .......
Once in January 2016 I was talking with someone who moved from Maine to suburban Virginia. She said the amount of snow dropped by the Snowzilla storm was more than what she was accustomed to seeing in Maine.
That sounded interesting, so I decided to look into it. I found a newspaper article that had data for the max 24-hour snowfall on a state-by-state basis. However, it was infuriating, because it was formatted as a flip-book, with one data point per page. There was no way to see all the data at once, hence no way to make comparisons.
Further digging turned up some NOAA data, sorted by state in alphabetical order. Now for some purposes that’s just what you want, but for other purposes not. The data was machine readable, so it took me only a moment to sort it in order of snowfall amount.
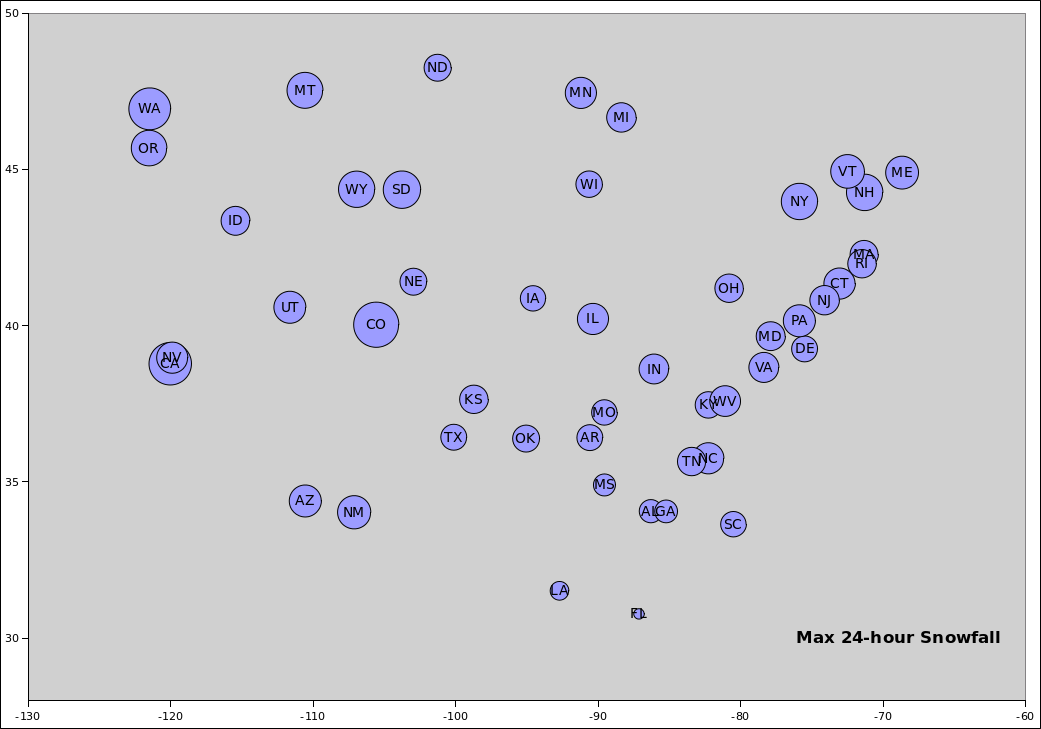
Looking at the sorted list made it clear that Colorado was ahead of California, but you had to expend some effort to understand what was a significant difference and what was not. So I made an analog list. The position of each state in figure 2 is proportional to the amount of snowfall.
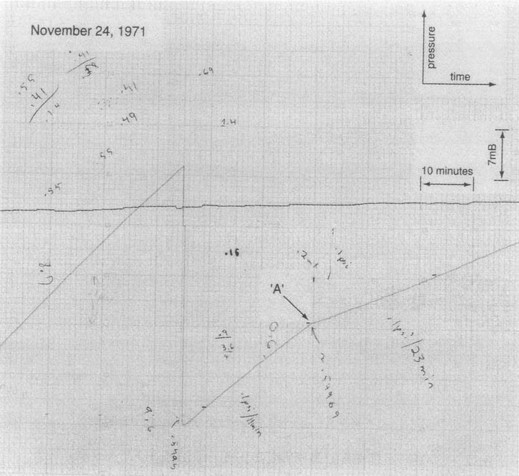
After looking at that, I decided it would be even better to visualize the geographic position as well as the snowfall amount. In figure 3, each bubble is centered on the place where the record snowfall actually fell (not centered on the middle of the state).
Note: This is better than what I saw in the newspaper, but still it’s not professional-grade data analysis. It’s just something I threw together on the spur of the moment. It could be improved in many ways. One obvious improvement would be to reformat the data as kml and display it using GoogleEarth. Examples of so-called “thematic mapping” can be seen at: http://thematicmapping.org/downloads/world_borders.php
Remarks: I find it a bit surprising that by this measure, Arizona and New Mexico are snowier than Idaho, North Dakota, Minnesota, and Michigan. Also, South Dakota is ranks much higher than North Dakota.
Remember that this is max snowfall in a single 24-hour period; it is not snow per storm, and certainly not snow per season.
Here are some useful general principles: