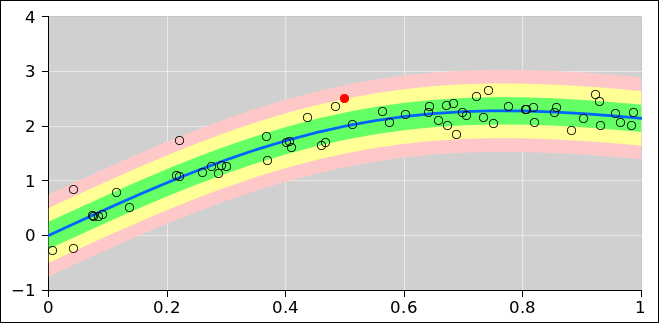
Figure 1: Fuzzy Rounding
Note the contrast:
| In every math book I’ve ever seen, the log(⋯) function is the base-e natural logarithm. The same goes for every non-spreadsheet computer language I’ve ever heard of. | In contrast, alas, excel decided to implement log(⋯) as the base-10 common logarithm. Other spreadsheet programs have followed suit. |
| This includes imperative languages such as C++ and functional languages such as lisp. | FWIW, a spreadsheet is considered more of a declarative language, as opposed to imperative or functional. |
This is a huge trap for the unwary. Constructive suggestion:
| When writing in a non-spreadsheet computer language, do not write log(⋯). Write ln(⋯) instead. If necessary, define your own ln function, e.g. #define ln(x) log(x). | When writing spreadsheet code, do not write log(⋯). Write log10(⋯) instead. That’s another name for the same built-in function. |
Note the contrast:
| In every math book I’ve ever seen, the floor(⋯) function rounds toward minus infinity (not toward zero). The same goes for every non-spreadsheet computer language I’ve ever heard of including imperative languages such as C++ and functional languages such as lisp. |
In contrast, alas, excel decided to
implement floor(⋯) as rounding toward zero. This
means it behaves like C++ int(⋯). Other spreadsheet programs have followed suit. |
This is another huge trap for the unwary. The only non-misleading workaround I know of is to avoid floor(x) and instead use -ceil(-(x)). See also section 1.1.4.
Meanwhile, the exist two spreadsheet functions, ceil(⋯) ceiling(⋯), which is a recipe for endless confusion. Spreadsheet ceil(⋯) is consistent with POSIX ceil(⋯); both round toward positive infinity. In contrast, ceiling(⋯) rounds away from zero.
In c++, perl, maxima, and many other languages, atan2(sin(-3), cos(-3)) is equal to -3. However, alas, in a spreasheet, it is not. The order of the arguments is reversed. You have to write atan2(cos(-3), sin(-3)).
This will drive you crazy if you are trying to explain something to somebody, and you don’t know what language they will be using.
There is no workaround that I know of. You just have to write different code in different situations.
Apparently it always rounds toward zero AFAICT, no matter what the prevailing FPU rounding mode might be. Alas I don’t know if/where this is documented.
As a consequence, when we evaluate y = int(x), the inverse image of y=0 is the entire open interval between −1.0 and 1.0, which is twice as big as the inverse image of any other integer.
To avoid this inconsistency, when converting something to an integer, consider round(x). That is almost the same as ceil(x - 0.5).
There is also a rint(⋯) function that rounds toward zero, plus infinity, minus infinity, or the nearest integer, depending on the prevailing FPU rounding mode.
See also section 1.1.2
The situation is summarized in the following table:
| C++ | | Spreadsheet | | Rounding Direction | | Substitute | |
| trunc(x) | | # | trunc(x) | | toward zero | | |
| int(x) | | ☠# | floor(x) | | toward zero | | trunc(x) |
| floor(x) | | ☠# | int(x) | | toward −∞ | | −ceil(−x) |
| ceil(x) | | # | ceil(x) | | toward +∞ | | |
| round(x) | | # | round(x) | | toward nearest integer | | |
| ??? | | ☠# | ceiling(x) | | away from zero | | avoid |
The # symbol indicates that the spreadsheet function implements fuzzy rounding, as discussed in section 1.5. The ☠ symbol indicates that the name is deceptive because it conflicts with the C++ function name. When designing spreadsheets, I avoid the deceptive int(⋯), floor(⋯) and ceiling(⋯) functions. Instead I use the more portable substitutes indicated in the table.
Apparently the spreadsheet gives negation (i.e. unary minus) higher precedence than exponentiation, so -5^2 is equal to +25. Yuck. (Other computer languages, along with every math book on earth, give higher precedence to exponentiation.)
Time-of-day is stored as a number, measured in days; for example, 6:00 AM is stored as 0.25. Dates are just long times, measured in days since 30-Dec-1899, or equivalently 367 + days since 1-Jan-1901. Some examples and a couple of screwy exceptions are discussed in section 1.3.
With a few important exceptions, the date-related arithmetic and plotting is agnostic as to timezones. You can read in a bunch of dates in the form 3-Nov-2016 12:00 and plot them without caring what timezone they belong to. You can by fiat declare all the dates in your document to be UTC ... or you can equally well declare them to be in your local timezone ... or almost anything else, so long as you are consistent about it.
The exceptions are:
="1-jan-1970"+date2unix(now())/86400
2023-07-05T13:35:15Z
The Z at the end denotes Zulu time (i.e. UTC). In this context, no other timezones are accepted, and the Z must not be omitted. The resulting cell value will be a date relative to UTC. It will not be converted to your local timezone, so it will not be consistent with the now() function. If you want consistency, you will have to write code to convert one or the other, using the offset described below.
If you get a date with an explicit nontrivial timezone offset, you can convert to UTC by using string functions to split off the offset, then recombining things. For example, let cells A5:A7 contain:
2023-07-05T16:39:39-07:00
=iferror(search("-",A6,search(":",A6)),search("+",A6,search(":",A6)))
=(mid(A6,1,A7-1)&"Z")-mid(A6,A7,99)
The offset of your local timezone relative to UTC (in days) is:
=mod(0.5+now()-date2unix(now())/86400,1)-0.5
If that’s in cell A1, you can pretty-print it as:
=if(A1<0,"−","+")&text(abs(A1),"h:mm")
Beware that all dates before 1-Mar-1900 are measured in days since 31-Dec-1899. That’s because some nitwit thought 1900 was a leap year. Dates after that are measured in days since 30-Dec-1899. Here are some key early dates:
| Day | ||
| Number | Date | |
| 0 | == | Sunday, December 31, 1899 |
| 1 | == | Monday, January 01, 1900 |
| 59 | == | Wednesday, February 28, 1900 |
| 60 | == | (not actually a date) |
| 61 | == | Thursday, March 01, 1900 |
| 365 | == | Sunday, December 30, 1900 |
| 366 | == | Monday, December 31, 1900 |
| 367 | == | Tuesday, January 01, 1901 |
Suppose we want to count from 0 to 15 in steps of 1/3rd. The recommended approach is to use integers to count from 0 to 45 (in column A below) and then divide by 3. This gives the best possible result, because integers can be represented exactly. There will be some roundoff error, but there will be no accumulation of roundoff error. In particular, the rows in column B that should contain integer values will indeed contain exact integer values, as you can see by looking at every third row in the table.
In contrast, it is a bad idea for each row to iteratively add 1/3rd to the previous row, as in column D. We see that many of the numbers that are supposed to be integers are not. The 0 row is exact, of course. The 1 row is also exact; evidently the roundoff errors have cancelled out. However, the 2 row is off by a bit, although it’s not off by much; only −1 units in the last place (ulp).
In the 6 row, column D is off by −2 ulp, and by the time we get to the 8 row, it’s off by −4 ulp. Note that because this is floating point, the size of a ulp depends on the magnitude of the associated number.
| A | B | C | D | E | F | G | H |
| 3 | 0.333333333333333315 | ||||||
| accurate | ☠ iterative ☠ | error/ulp | fuzzing worthwhile? | ||||
| 0 | 0.000000000000000000 | 0.000000000000000000 | 0 | not necessary | |||
| 1 | 0.333333333333333315 | 0.333333333333333315 | 0 | ||||
| 2 | 0.666666666666666630 | 0.666666666666666630 | 0 | ||||
| 3 | 1.000000000000000000 | 1.000000000000000000 | 0 | not necessary | |||
| 4 | 1.333333333333333259 | 1.333333333333333259 | 0 | ||||
| 5 | 1.666666666666666741 | 1.666666666666666519 | -1 | ||||
| 6 | 2.000000000000000000 | 1.999999999999999778 | -1 | not necessary | |||
| 7 | 2.333333333333333481 | 2.333333333333333037 | -1 | ||||
| 8 | 2.666666666666666519 | 2.666666666666666519 | 0 | ||||
| 9 | 3.000000000000000000 | 3.000000000000000000 | 0 | not necessary | |||
| 10 | 3.333333333333333481 | 3.333333333333333481 | 0 | ||||
| 11 | 3.666666666666666519 | 3.666666666666666963 | 1 | ||||
| 12 | 4.000000000000000000 | 4.000000000000000000 | 0 | not necessary | |||
| 13 | 4.333333333333333037 | 4.333333333333333037 | 0 | ||||
| 14 | 4.666666666666666963 | 4.666666666666666075 | -1 | ||||
| 15 | 5.000000000000000000 | 4.999999999999999112 | -1 | not necessary | |||
| 16 | 5.333333333333333037 | 5.333333333333332149 | -1 | ||||
| 17 | 5.666666666666666963 | 5.666666666666665186 | -2 | ||||
| 18 | 6.000000000000000000 | 5.999999999999998224 | -2 | not necessary | |||
| 19 | 6.333333333333333037 | 6.333333333333331261 | -2 | ||||
| 20 | 6.666666666666666963 | 6.666666666666664298 | -3 | ||||
| 21 | 7.000000000000000000 | 6.999999999999997335 | -3 | not necessary | |||
| 22 | 7.333333333333333037 | 7.333333333333330373 | -3 | ||||
| 23 | 7.666666666666666963 | 7.666666666666663410 | -4 | ||||
| 24 | 8.000000000000000000 | 7.999999999999996447 | -4 | not necessary | |||
| 25 | 8.333333333333333925 | 8.333333333333330373 | -2 | ||||
| 26 | 8.666666666666666075 | 8.666666666666664298 | -1 | ||||
| 27 | 9.000000000000000000 | 8.999999999999998224 | -1 | not necessary | |||
| 28 | 9.333333333333333925 | 9.333333333333332149 | -1 | ||||
| 29 | 9.666666666666666075 | 9.666666666666666075 | 0 | ||||
| 30 | 10.000000000000000000 | 10.000000000000000000 | 0 | not necessary | |||
| 31 | 10.333333333333333925 | 10.333333333333333925 | 0 | ||||
| 32 | 10.666666666666666075 | 10.666666666666667851 | 1 | ||||
| 33 | 11.000000000000000000 | 11.000000000000001776 | 1 | –some effect– | |||
| 34 | 11.333333333333333925 | 11.333333333333335702 | 1 | ||||
| 35 | 11.666666666666666075 | 11.666666666666669627 | 2 | ||||
| 36 | 12.000000000000000000 | 12.000000000000003553 | 2 | not sufficient | |||
| 37 | 12.333333333333333925 | 12.333333333333337478 | 2 | ||||
| 38 | 12.666666666666666075 | 12.666666666666671404 | 3 | ||||
| 39 | 13.000000000000000000 | 13.000000000000005329 | 3 | not sufficient | |||
| 40 | 13.333333333333333925 | 13.333333333333339255 | 3 | ||||
| 41 | 13.666666666666666075 | 13.666666666666673180 | 4 | ||||
| 42 | 14.000000000000000000 | 14.000000000000007105 | 4 | not sufficient | |||
| 43 | 14.333333333333333925 | 14.333333333333341031 | 4 | ||||
| 44 | 14.666666666666666075 | 14.666666666666674956 | 5 | ||||
| 45 | 15.000000000000000000 | 15.000000000000008882 | 5 | not sufficient |
Note that iterative addition is a very simple calculation. There are lots of more complicated calculations where the accumulated roundoff error is very much greater than 1 ulp.
The concepts in this subsection don’t have much to do with spreadsheets per se; mostly they apply to floating-point calculations in general. There’s a lot more that could be said about this. There are fat books on the topic of numerical analysis.
In contrast, the next subsection covers some similar issues that are inherently peculiar to spreadsheets.
| Beware that spreadsheet functions such as ceil(⋯), and trunc(⋯) implement a form of fuzzy rounding. That is, if the input is within 1 ulp of an integer, they use the integer instead. | In C programs, POSIX library functions such as ceil(⋯) etc. implement ordinary non-fuzzy rounding. |
| Similarly, spreadsheet functions such as round(⋯) use fuzzy rounding in the vicinity of half-integers. |
The fuzz issue is not super-important, because the errors it introduces are small. Meanwhile, floating point operations necessarily involve rounding, which introduces errors (on top of any fuzz-related errors). In multi-step calculations, the accumulated errors are commonly much larger that 1 ulp; the table above gives a hint of this. Decent algorithms do not assume the errors are 1 ulp or less; they are designed to cope with much larger errors.
fin
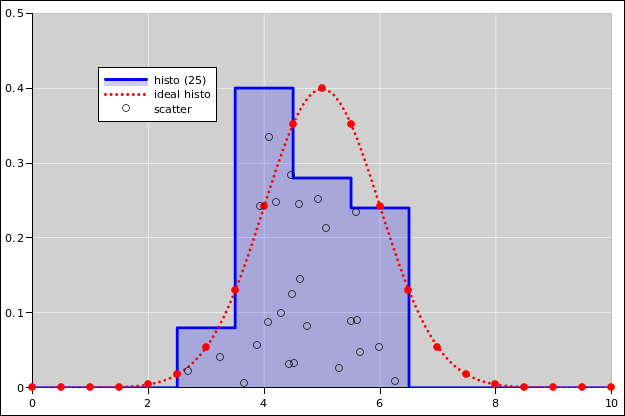
You can see in figure 1 that one of the floating-point codes that should have been rounded up was not.
You can sorta imagine where this scheme come from. Somebody wanted to keep users from being surprised when numbers that were “almost” integers behaved strangely. Note that all the near-integers in the table in section 1.4 would seem to be exact if displayed with 14 or fewer decimal places, so the roundoff errors would not be super-obvious.
However, this is a fool’s errand. You can see in the table that out of 16 near-integers, there is only one case where fuzzy rounding has any effect at all. In 11 of the cases it isn’t necessary (because the number is already exact, or because the error is in a direction where it does no harm), and in 4 of the cases it isn’t sufficient (because the accumulated roundoff error is greater than 1 ulp). Even in the one case where there is some effect, it’s not clear that it’s a good effect. It creates a situation where ceil(x) is less than x, which seems like a Bad Thing.
All in all, the fuzzy rounding scheme adds to the complexity without solving any problems worth solving.
The only non-foolish procedure is to design your algorithms so that they are not sensitive to what’s going on in the 16th decimal place. If you need mathematical exactitude, use integers and rational numbers. The spreadsheet app uses the double data type for everything, which can represent integers exactly (if they’re not too huge). It can also express rational numbers of the form A/2B, where A and B are integers. For example, 3/16ths is represented exactly.
Workarounds:
=(ceil(A1)+(ceil(A1)<A1))
The term “fencepost problem” alludes to the proverbial long straight fence where there are N lintels held up by N+1 posts.
This is relevant in many different computing situations, especially when an interval is divided into N subintervals (not necessarily all the same size) demarcated by N+1 endpoints. In particular, this is relevant to running sums, simple numerical integrals, simple numerical derivatives, and anything else where you might have stairsteps, treads, risers, or a threatened mismatch between posts and lintels.
By far the slickest way to proceed is to put both the start and the end of each interval on the same row. So the row contains a lintel. The fenceposts are duplicated, because the right end of this row appears again as the left end of the next row.
xleft xright yleft yright deriv deriv
1 2 f(1) f(2) d12 d12
2 3 f(2) f(3) d23 d23
3 4 f(3) f(4) d34 d34
This gives us a chordwise representation of the function f(). That is, it draws the chord line from (1, f(1)) to (2, f(2)).
You can calculate the numerical derivative as (yright-yleft)/(xright-xleft). It is a property of the interval, i.e. of the lintel, not a property of either fencepost. So put the value of the derivative in two successive columns.
This gives us a treadwise representation of the derivative f’(). That is, each row represents a tread, as the x variable advances. Risers happen between rows, as the f’() ordinate advances from d12 to d23.
You can devertialize the risers by shifting the top half a tread-width in one direction and shifting the bottom by half a tread-width in the other direction. If the derivative has a sharp corner in it (large second derivative) this doesn’t solve all the world’s problems, but it’s still a reasonable thing to do.
Often you want to do interpolation. That requires the abscissas to be strictly sorted. To arrange that, create two more columns, namely xleft*(1+delta) and xright*(1-delta), where delta is approximately the square root of the machine epsilon; that is, delta is about 1e-8. Then you can interpolate, using an N×2 array of abscissas and an N×2 array of ordinates.
Similarly the integrand is a property of the interval. The integral is the sum over intervals, summing the measure associated with the intervals. This allows you to find the resulting integral at the endpoints of the interval.
The following is not very convenient. Use the methods outlined in section 1.6.1 instead.
As a corollary, this means that each lintel is indexed accoreding to the post at the left end of the lintel, i.e. the lesser-numbered of the two posts that hold that lintel.
Format all the lintel-values as subscripts, and all the post-values as superscripts. This makes it easier to visualize the idea that the lintels fall between the posts. Alas the contrast between subscripts and superscripts is not as striking as one might have hoped, but it’s better than nothing. The goal is to get a spreadsheet that looks something like this:
| post | lintel |
| 0 | |
| 0 | |
| 1 | |
| 1 | |
| 2 | |
| 2 | |
| 3 |
Let’s assume you have column vectors, not row vectors. Put the formula in the top cell of the result. Replace V$1 by the top of one of your vectors (two places), and W$1 by the top of the other (two places). Be sure to spell it with a $ sign in front of the row-number. Enter it as a regular (non-array) expression in the top cell of the result, then fill down into the remaining cells.
Even though the formula mentions cell A1, we do not care what (if any) value is there.
=offset(V$1,mod(1+row($A1)-row($A$1),3),0)*offset(W$1,mod(2+row($A1)-row($A$1),3),0) -offset(V$1,mod(2+row($A1)-row($A$1),3),0)*offset(W$1,mod(1+row($A1)-row($A$1),3),0)
For row vectors, the corresponding formula is:
=offset($V1,0,mod(1+row(A$1)-row($A$1),3))*offset($W1,0,mod(2+row(A$1)-row($A$1),3)) -offset($V1,0,mod(2+row(A$1)-row($A$1),3))*offset($W1,0,mod(1+row(A$1)-row($A$1),3))
In typical spreadsheets, curly braces are used to denote an array constant, for example {1,2,3} is a horizontal array. Similarly, {5;6;7} is a vertical array constant. Continuing down this road, {11,12,13;21,22,23;31,32,33} is a 3×3 matrix constant. The general rule is that commas are used to separate values on any given row, while semicolons are used to separate rows.
Here are some example of how this can be used:
=sum(row($A$1:$A$10))
(not necessarily entered as an array formula)
To generate <nval> values starting from <start>:
=row(offset($A:$A,start-1,0,nval,1))
Additional applications of this idiom can be found below.
Hamming weight =sum(bitand(1,C9/2^(row($A$1:$A$64)-1)))
Hamming distance =sum(bitand(1,bitxor(C9,C10)/2^(row($A$1:$A$64)-1)))
parity =bitand(1,sum(bitand(1,C9/2^(row($A$1:$A$64)-1))))
String initial match =sum(if(left(C6,row(offset($A:$A,0,0,len(C6),1)))=left(C7,row(offset($A:$A,0,0,len(C6),1))),1,0))
=sum(normdist(K10,AA$11:BD$40,K$4,0)*K$2)
Explanation: The normdist() function ordinarily returns a scalar. If however you pass an array expression (constant or otherwise) as one of its arguments, it returns an array. This is an ephemeral array, not visible on the spreadsheet anywhere. In this example, the sum() collapses the ephemeral array, producing a scalar that fits in a single cell. Remember to enter the expression using <ctrl-shift-enter>.
Hint: If you ever enter something as a scalar when you should have entered it as an array, don’t panic. The formula is still there, and can easily be promoted to array-formula status. Highlight the area that is to be filled by the array, hit the <F2> key to move the focus to the formula bar, and then hit <ctrl-shift-enter>.
As we have seen in the examples above, you can do arithmetic involving array constants, for instance by highlighting cells A1:C1, then typing in =10^{1,2,3} and hitting <ctrl-shift-enter>. This will put the values 10, 100, 1000 into the three cells.
Obviously you can compute the maximum of these three cells using the expression max(A1:C1), and store this result in a single cell such as A3.
Logic suggests that you can do the same thing on the fly, by entering the combined expression max(10^{1,2,3}) into a single cell such as B3.
However, beware: Due to a bug in current versions of the gnumeric spreadsheet program, and possibly other programs as well, if you try in the normal way, you will get a numerically-wrong answer. See reference 3.
As a workaround for this bug, you can get the right answer by entering the formula =max(10^{1,2,3}) as an array formula using <ctrl-shift-enter>. There is no good reason why <ctrl-shift-enter> should be needed in this situation, because we are entering an ordinary scalar-valued expression, equivalent to the expression in the previous paragraph (which did not require <ctrl-shift-enter>).
Suppose you have data in columns B through E, and you want to make a copy with the columns in reverse order. You can use the following:
=offset($B2,0,column($E2)-column(B2))
| | |
first last first
column column column
I prefer offset, but you can use index() instead if you want. It starts counting at 1, whereas offset() starts counting at 0. Also, index requires an array as its first argument, while for present purposes offset requires a single cell as its first argument (since we want each call to offset to yield a single cell).
=index($B2:$E2,1,1+column($E2)-column(B2))
Fill across to cover all the columns of interest. Fill down if there are multiple rows in each column. (This is not meant to be entered as an array formula.)
Similarly, to reverse rows:
=offset(B$2,row(B$5)-row(B2),0)
| |
top bottom
row row
or perhaps equivalently
=index(B$2:B$5,1+row($B$5)-row($B2),1)
Fill down to cover all the rows of interest. Fill across if there are multiple columns of in each row. (This is not meant to be entered as an array formula.)
Finally, to flip both the rows and the columns all at once (i.e. a 180∘ rotation):
=offset($B$2,row(B$5)-row(B2),column($E2)-column(B2))
| | |
upper upper lower
left right left
Fill down and fill across to cover all the rows and all the columns.
It would be super-nice to be able to express the reverse as an array expression, but I have not found a way to do this. The index() and offest() functions do not appear to tolerate array expressions in their second or third arguments.
Reversing turns out to be important in connection with convolutions.
Multiplying two polynomials is convolution-like. Start by reversing one of the multiplicands (i.e. reversing the list of coefficients). Then use a formula like this:
=sumproduct(offset(M4,0,0,1,1+AA$2),offset($AC3,0,0,1,1+AA$2))
Another important application arises in connection with a band plot such as in figure 3. Ideally it would be possible to make such a plot using the "fill to next series" feature of the spreadsheet program, but in older versions of gnumeric that has bugs. It is better to use the "fill to self" feature. This requires tracing the top of each band in the normal order, then tracing the bottom of each band in reverse order.
See reference 2.
Here is an example of a convolution:
npts: 8 =sumproduct(offset($B$10,max(0,row(A1)-$C$7),0,min(row(A1),2*$C$7-row(A1))),offset($D$10,max(0,$C$7-row(A1)),0,min(row(A1),2*$C$7-row(A1))))
=offset($C$10,$C$7-row(A1),0)
label
0 0 0 0 0
1 1 1 1 0
2 1 1 1 1
3 1 1 1 2
4 1 1 1 3
5 1 1 1 4
6 1 1 1 5
7 0 0 0 6
8 5
9 4
10 3
11 2
12 1
13 0
14 0
where cell $c$7 contains the number of points in each vector (npts: 8) and the first vector begins at $b$10 and the second begins at $c$10. The reverse of the second vector begins at $d$10.
Suppose you have a row of data: 1, 2, 3, et cetera. You would like to plot each data item twice. Usually the best way to do this is to put the duplicates in adjacent rows as discussed in section 1.26.
However, sometimes you might want to keep everything in a single row, and just have twice as many cells in the row, so that the row reads 1, 1, 2, 2, 3, 3, et cetera. This situation can easily arise if you want to draw a stair-step function. The vertical risers require you to duplicate the abscissas, and the horizontal treads require you to duplicate the ordinates.
The index function can do this for you:
=index($I11:$W11,1,1+(column(I11)-column($I11))/2)
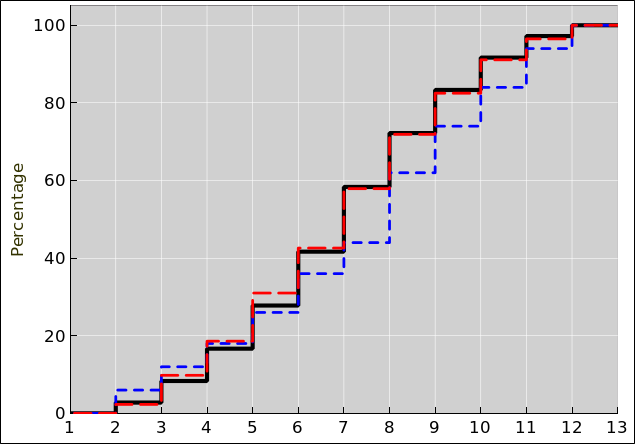
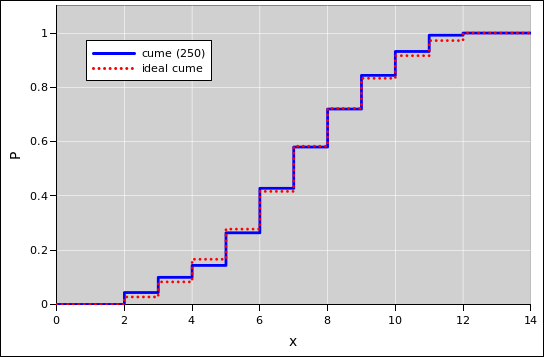
Note that stair-steps arise if you are plotting the cumulative probability for a discrete distribution, such as in figure 4.
The column(M7) function returns the address of the given column; in this example, “M” is column number 13. If however you want the column letter, aka the column name formatted as a letter, you have to work harder. Here’s the recommended expression:
=substitute(address(1,column(M7),4),"1","")
Explanation: The row number (“7”) here is irrelevant. The column(M7) function returns 13, ignoring the row number. The address(...,4) function returns an address, namely the text string “M1”. The “4” here tells it to return a relative address (i.e. without any $ signs). Lastly, we get rid of the “1”.
Here’s one rationale for doing something like this: Suppose you want to format a message that refers to the column in which cell M7 was found. Next, suppose you cut-and-paste cell M7 to a new location such as N8. The result of the recommended expression will change accordingly; the new result will be “N”. In other words, the recommended expression is translation invariant – whereas a simple string constant (in this case “M“) would not be.
In some cases there are simpler ways of achieving translation invariance, as discussed in section 1.16.
Use the match(needle,haystack,0) to return a relative row number. A result of 1 corresponds to the first row in the haystack range. In particular, argmax is match(max(haystack),haystack,0) and argmin is match(min(haystack),haystack,0).
The result can then be used in the index(range,relRow,relCol) function to fetch a value. Equivalently, it can be used in the offset function, provided you subtract 1.
To sort numbers in ascending order:
=small($D$4:$D$99,1+row($D4)-row($D$4)) <E>
where <E> means you can enter it as a plain old scalar formula (not array formula).
Step 1: To get an array of indices, apply the following to the sort key, to encode the key and the corresponding row number. In this example, the input data starts at D$4.
=round(percentrank(D$4:D$99,D4,20)*(count(D$4:D$99)-1))+(row($d4)-row($d$4))/1000 <E>
Format that with three decimal places.
See section 1.19 for a discussion of the percentrank function. Let N denote the number of valid elements. Multiplying the prank by N−1 (and rounding) gives the rank as an integer (with N possible values from zero to N−1 inclusive). We use the integer rank as our sort key. The rest of the expression uses the fraction part to encode the index, to remember where this element was before sorting.
Step 2: Sort the indices. Suppose the keys are in column A and we want the sorted results in column B:
=small(A$4:A$99,1+row($B4)-row($B$4))
or
=large(A$4:A$99,1+row($B4)-row($B$4))
Then extract the row number, which serves as an index:
=round(mod(B4,1)*1000)
Or combine the two previous steps, to calculate the index directly:
=round(mod(small(A$4:A$99,1+row($B4)-row($B$4)),1)*1000)
=round(mod(large(A$4:A$99,1+row($B4)-row($B$4)),1)*1000)
Then you can use offset(...) to fetch all the sorted field(s) you want, not just the sort key field.
=offset(x!D$2,$B2,0) <E>
Fill that across (to pick up all fields) and down (to pick up all records) as required.
You can check for ties by looking at the ascending and descending pranks; they should add up to unity:
=percentrank(D$2:D$6,H2,20)
=percentrank(iferror(-D$2:D$6,"x"),-H2,20)
This makes sense insofar as it is 1/(N−1) less than the prank of the next-larger element of the haystack, i.e. Rnext = Rlow + M/(N−1)
To find the number of valid numeric elements in a region, ignoring strings, empty cells and #ERROR cells, use the following, entered as an array formula:
=count(B15:C17)
or equivalently
=sum(iferror(B15:C17-B15:C17+1,0)) (array formula)
If you want something that does not ignore #ERROR cells, try something like this:
=rank(max(B15:C17),B15:C17,1)+sum(if(B15:C17=max(B15:C17),1,0))-1
If there are one or more errors anywhere in the range, the result will be an error. The type of the result error will match one of the input errors.
Interpolation is very much more forgiving (compared to lookups) if the abscissas aren’t exact.
Beware that the interpolation() function insists on performing extrapolation if it runs out of ordinates. Blank ordinates are not the same as zeros, but you can fix this by writing “0+range” instead of simply “range” in the second argument, as in the example in section 1.21.2.
Avoid using a multi-column area as the second argument of vlookup(), or more to the point, avoid using any number other than 1 as the third argument (the readout column). That’s because anything that requires you to count columns is bug-bait. In particular, if somebody ever wants to insert or remove a column from your table, it will break things.
Instead, use a one-column area as the second argument, set the third argument to 1, and also set the fourth argument to 1 so that vlookup() returns an index. Then feed that index to offset() to grab the desired element from the appropriate column. This makes your spreadsheet vastly more reliable, more debuggable, more maintainable, and more extensible.
For example, instead of:
=vlookup(B19-$H$12,$B$19:$I$138,8,1)
you might be a lot happier with:
=offset($I$19,vlookup(B19-$H$12,$B$19:$B$138,1,1),0)
and even happier with:
=interpolation($B$19:$B$138,0+$I$19:$I$138,B19+$H$12)
Similary words apply to hlookup().
Sometimes you want to select a subset of the original data, and put it into a new region without gaps. This is called a query. You might want to run multiple queries against the same original data.
As a particularly simple example, suppose you want to select all the valid data, squeezing out non-numerical entries (such as blank cells, strings, and #ERROR cells) to produce a result with no gaps.
Suppose the original data is in cells a6:c37. That’s a total of N=32 rows. Columns B and C can be used for some related (or unrelated) purpose.
Let’s skip a column (D) for clarity.
Use column E to keep a running sum of how many times the selection criterion is met. There has to be a zero in cell E5. Then in E6 we use the formula:
=if(count(A6), round(E5)+1, E5+1e-9)
where the first argument to the if(,,) statement is the criterion; it should evaluate to true whenever the criterion is met, and false otherwise. Note the 1e-9 which is necessary to make sure the elements in this column are strictly sorted, as required by vlookup(). The idea is that each valid entry gets an integer sequence number, while invalid entries get a non-integer.
This is not an array formula. Fill down so there are N−1 rows of this formula (following the zero in cell E5).
Then in the next column (F), find where each successive match occurs. Vlookup returns a 0-based index into the original data. When exact matching is in effect, it returns -1 when there is no match.
=vlookup(1+row()-row($F$6),E$6:E$24,1,0,1)
The second argument to vlookup is the column to be searched. The fifth (i.e. last) argument says we want an index, which means the third argument is irrelevant, but it is not ignored, so it has to be 1. The fourth argument is 0 which means we don’t want an approximate match; instead we insist on an exact match. (Otherwise it would be much harder to deal with the end of the result region, where there are no valid matches.)
Then in the next column (G) we collect the results.
=if($F6>=0,offset(B$6,$F6,0),"xxx")
That can be filled down and across as much as you like. Filling across picks up data from columns B and C, but the validity decision is still based on column A.
When plotting, in the simplest case, the ordinate of the plot is a one-dimensional spreadsheet region, by which I mean a region that is either N rows by 1 column, or 1 row by N columns. (Ditto for the abscissa, if any.)
However, it is perfectly possible for the ordinate (and/or abscissa) to be a rectangular region, with M rows and N columns. The region is read in row-major order; that is, every cell in a given row is read out before advancing to the next row. For example, the region A1:C10 contains 30 elements, in the following order A1, B1, C1, A2, ⋯ B10, C10.
It is reasonably straightforward to plot a set of arbitrary line segments (disconnected from each other). Similarly it is reasonably straightforward to plot a set of arbitrary triangles or other polygons.
The basic idea is to plot them as an ordinary “XY lines” plot. To separate one item from the next, put a non-numeric value in the list of abscissas and/or ordinates. A blank will do, it is more readable if you use a string such as “break” or “X”.
This idea combines nicely with the rectangular regions discussed in section 1.23. To plot N line segments, use three columns of N rows for the abscissas (tail.x, tip.x, and “break”) plus three columns for the ordinates (tail.y, tip.y, and “break”).
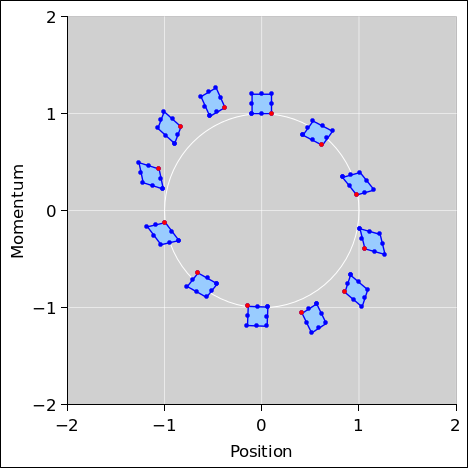
Similarly, to plot N quadrilaterals, use six columns of N rows; the first four define the corners, the fifth returns to the starting point to close the last side, and the sixth is the “break”. An example is shown in figure 5.
If you don’t need to close the last side, you can get by with only five columns. For an example, see figure 9 in section 2.1.
For a triangular distribution with a mean of 0, a height of 0.5, and a HWHM of 1 (HWBL of 2), the probability density distribution is:
=(0.5-abs(C5/4))*(abs(C5)<2)
This assumes you have already, in a previous step, normalized the data by subtracting off the mean and dividing by the HWHM. Furthermore, you will have to postmultiply the density by the inverse of the actual HWHM, so that the area under the curve will be unity.
The corresponding cumulative probability distribution is:
=if(abs(C5)<2,0.5+C5/2-C5*abs(C5)/8,(sign(C5)+1)/2)
For a rectangular distribution with a mean of 0, a height of 0.5, and a HWHM of 1 (HWBL also 1), the probability density distribution is:
=(abs(C5)<1)/2
This assumes you have already, in a previous step, normalized the data by subtracting off the mean and dividing by the HWHM. Furthermore, you will have to postmultiply the density by the inverse of the actual HWHM, so that the area under the curve will be unity.
The corresponding cumulative probability distribution is:
=if(abs(C5)<1,0.5+C5/2,(sign(C5)+1)/2)
For a discrete distribution, such as we get from rolling a die, cumulative probability is a stairstep function. Suppose there are N steps. Depending on details of the desired appearance, this will correspond to either N treads and N+1 risers, or perhaps N+1 treads and N risers. Either way, there is a nice representation using N+1 rows of four columns: two columns for the abscissas, and another two columns for the ordinates. Each row represents one tread: It has two unequal abscissas (the left edge and the right edge of the tread) and two equal ordinates (since the tread is horizontal).
For an example, see section 2.1.
In order to understand what gets plotted in front of what, it helps to know some terminology. However, the terminology for graphical objects is maddening. You might imagine that words like graph, chart, and plot should mean pretty much the same thing ... but in this context they don’t. I write these words in small caps to indicate that they are codewords.
Gnumeric doesn’t even use its own terminology consistently. The popup for customizing a graph and its contents is entitled «Customize Chart» whether or not the graph contains zero, one, or many charts.
Here is a subset of what is going on, even when you try to do something simple. Suppose we are making an XY plot of some data:
In contrast, the size and position of the plots is controlled by properties of the parent chart – not by the axes, and not by the plots themselves. Don’t ask me to explain this.
Now, you might imagine that the drawing routines would recurse through the objects pretty much as shown above. In particular, you might imagine that gnumeric would finish drawing one series before going on to the next. However, that’s not how it actually works. The innermost loops are done “inside out” as explained below. This is completely undocumented, indeed contrary to the documentation.
The actual behavior can be outlined in pseudocode, as follows:
foreach plot in chart.children {
foreach drawable in [line, symbol] {
foreach series in plot.children {
draw(series, drawable)
}
}
}
In English, that means that within each plot, the lines (for all the series) are drawn in order, and then the symbols (for all the series) are drawn in order. All of the lines wind up behind all of the symbols. The stacking of the lines (relative to other lines) is controlled by the order of the series as they appear in the user interface, and similarly for the stacking of the symbols (relative to other symbols). However, within a plot, there is no way to draw a line on top of a symbol ... even if you have one series that uses only lines and another that uses only symbols. No amount of re-ordering the series within a plot will change this.
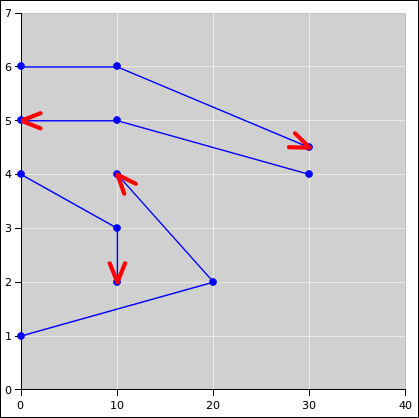
This ordering may not be what you want. (An example arises when plotting arrowheads on top of target symbols, as discussed in section 1.28.) In such a case, the only way to make progress is to use more than one plot, and order the plots appropriately. You can achieve quite fine control over the “stacking” – i.e. the order of plotting – by putting each series in its own plot. Use one series per plot, i.e. one plot per series.
For even finer control of the plot order, don’t rely on a single series to draw both lines and symbols. Instead, split it into two series looking at the same data. One series displays the lines, while the other series displays the symbols.
This business of creating more than one plot would be a lot more practical if it were possible to move a series from one plot to another, but evidently that is not possible. The buttons that move a series up and down in plot order get stuck at the boundary between plots.
While we’re on the subject: What would help most of all is the ability to copy-and-paste a series ... and also copy-and-paste an entire plot (along with all its series). This includes being able to copy a series from one plot and paste it into another. The ability to copy-and-paste (not just cut-and-paste) has innumerable applications. It is very common to want a new curve that is just like an old curve, with minor modifications.
It is important to distinguish between data space and screen space.
There are some things such as arrowheads that clearly need to be plotted in screen space, not data space. You want the arrowhead shape to be preserved, even if it is rotated by some odd angle. The idea of rotation makes sense in screen space, but violates basic requirements of dimensional analysis in data space, where there is not (in general) any natural metric, i.e. not any natural notion of distance or angle.
In figure 6, the extent of the plot in the x direction is more than fivefold larger than the extent in the y direction. The arrowheads would be grossly distorted if we tried to draw them in data space without appropriate correction factors.
Although typical spreadsheet apps do not provide easy access to screen space, we can work out the required transformations. The first step is to figure out the metric. We know the metric in screen space, and we use this to construct a conversion metric for data space. Let’s denote data space by (x, y) and screen space by (u, v).
In data space, the metric has the trivial, obvious form:
|
In data space, we assume the conversion metric tensor can be written
in the form:
|
Equivalently, this idea can be expressed in terms of the element
of arc length:
|
Equivalently, the conversion can be expressed in terms of the element
of arc length:
|
It must be emphasized that the arc length ds is the same in both equation 3 and equation 4. It is the real physical arc length on the screen.
You can determine the coefficients a and b as follows: Lay out a rectangle on the chart. Let the edges of the rectangle be (Δu, Δv) in screen space, and (Δx, Δy) in data space. Then the needed coefficients are:
| (5) |
The conversion metric defines a notion of length and angle in data space. Given a line segment in data space, we can construct a tangent unit vector with the same orientation ... where “unit” refers to its length in screen space. We can also define a transverse unit vector, perpendicular to the line segment ... where “perpendicular” refers to its angle in screen space.
It is then straightforward to construct arrowheads and other objects in terms of the tangent unit vector and the transverse unit vector.
If you change the size of the chart or rescale the axes within a chart, you will have to recompute the a and b coefficients in accordance with equation 5. This is a pain in the neck if the axis bounds are being computed automatically.
Before you start plotting arrowheads, be sure to read section 1.27. You may want to use the one-plot-per-series construction for your vectors and arrowheads.
The spreadsheet code to do this is cited in reference 4. In this example, the plotting area is square, and the edge-length of the plotting area is taken as the unit of distance in screen space. The size of the arrowheads is 1/20th of this distance. This is of course only an example; any other distance could be used in accordance with equation 5.
There are several ways to see the formula aka expression in a cell (as opposed to the value obtained by evaluating the expression).
I use this a lot. It is useful in pedagogical situations, where you want people to be able to see the formula and the value at the same time. It is also useful as a way to put formulas and/or addresses into a .csv file, which (as the name suggests) nominally only includes values. There are lots of good reasons why you might want formulas and/or addresses in .csv files.
Sometimes it is useful to turn of the “Automatic Recalculation” feature. Examples include
You can manually cause a new calculation at any time by hitting the <F9> key.
The default format that gnumeric uses for storing spreadsheet documents is structured as XML. Often there is gzip compression on top of that, but uncompressing it is super-easy.
(I have no idea what format excel uses.)
It is fairly easy to figure out what the XML means, and then to munge it using a text editor, or using tools such as grep, awk, perl, et cetera.
For example, suppose you want to have a plot with 35 curves on it. Configuring all of those using the point-and-click interface is unpleasant the first time, and even more unpleasant if you want to make a small change and then propagate it to all the clones. Therefore I wrote a little perl program that take one curve (aka Series) as a template and then makes N clones.
The spreadsheet in reference 6 calculates the probabilities for a pair of dice. Look at the “histo-2-efficient” worksheet.
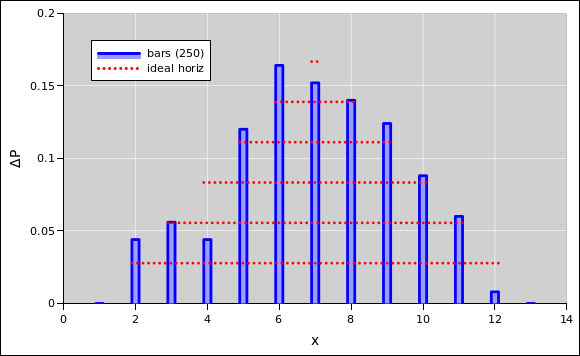
|
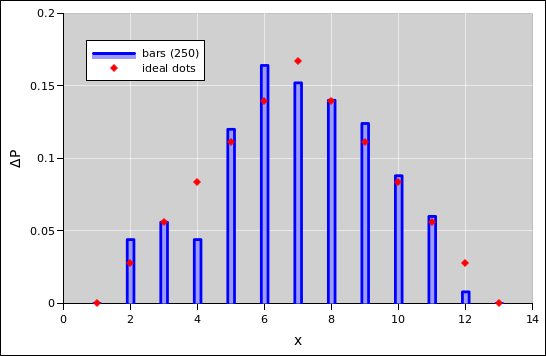
| |
| Figure 9: Two Dice : Probability Histogram + Horizonal Lines | Figure 10: Two Dice : Probability Histogram + Dots | |
Note the following:
Therefore it is better to use the approach seen in figure 9 and figure 10. They plotted the histogram as a bunch of quadrilaterals, using the techniques mentioned in section 1.24.
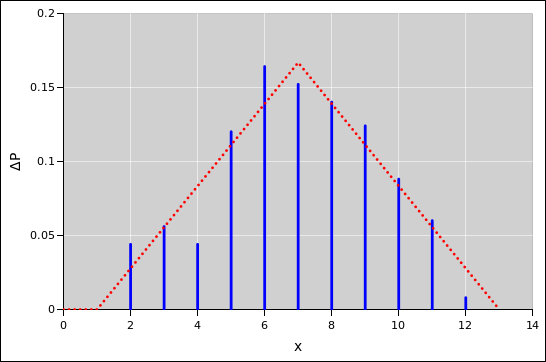
For a continuous probability distribution, the right approach is to sort the data. Then the index (suitably normalized) is the cumulative probability, as a function of the data value. That is to say, there is a riser at every data point, and a tread between each two data points. See section 2.2 and reference 7.
For discrete data, with relatively few categories, sorting is inefficient and unnecessarily complicated.
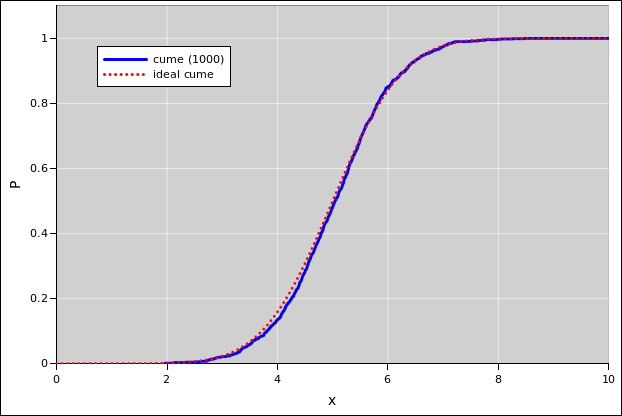
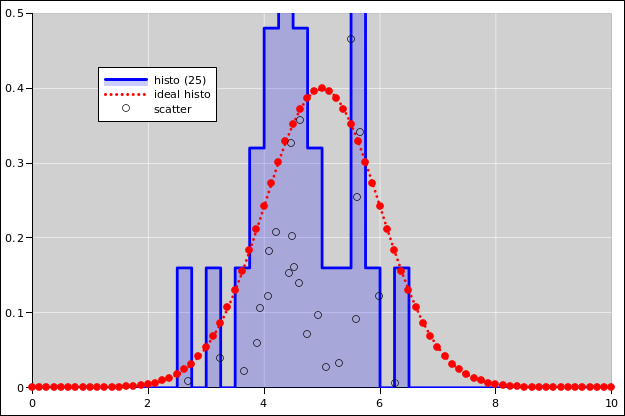
|
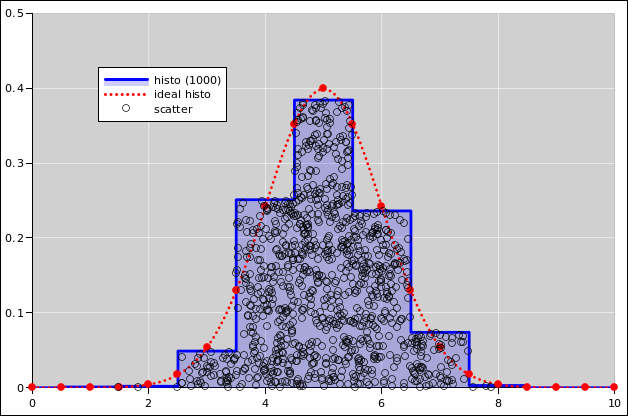
| |
| Figure 11: Gaussian Cumulative Probability Distribution | Figure 12: Gaussian Probability Density Distribution | |
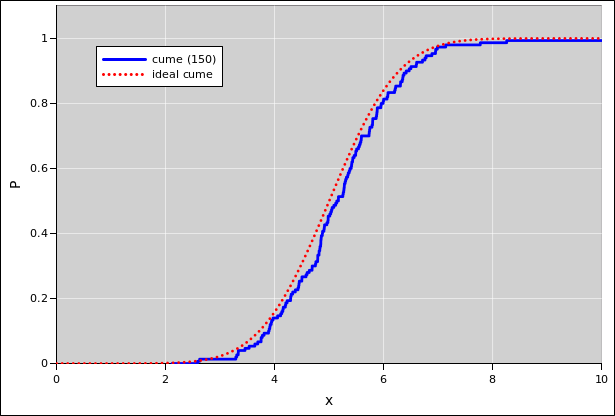
|
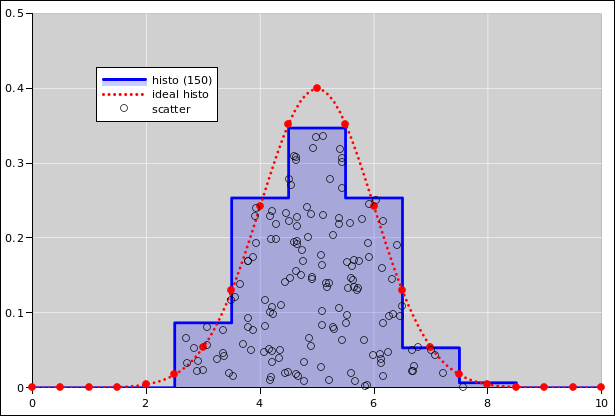
| |
| Figure 13: Gaussian Cumulative Probability Distribution | Figure 14: Gaussian Probability Density Distribution | |
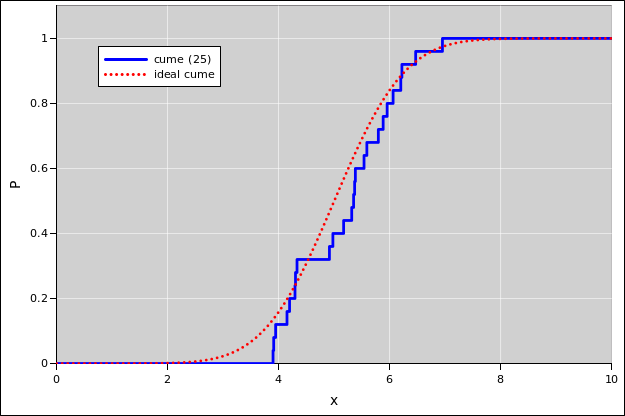
|
| |
| Figure 15: Gaussian Cumulative Probability Distribution | Figure 16: Gaussian Probability Density Distribution | |
See reference 7.
For plotting the cumulative probability distributions, the following statement comes in handy:
=if(J8<1,small(offset($E$8,0,0,G$4),1+row($$E8)-row($E$8)),9e+99)
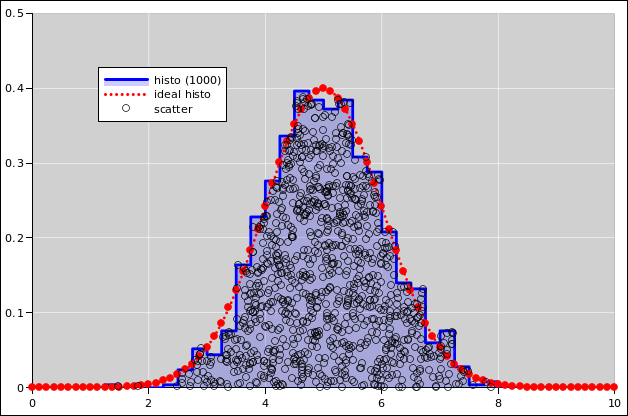
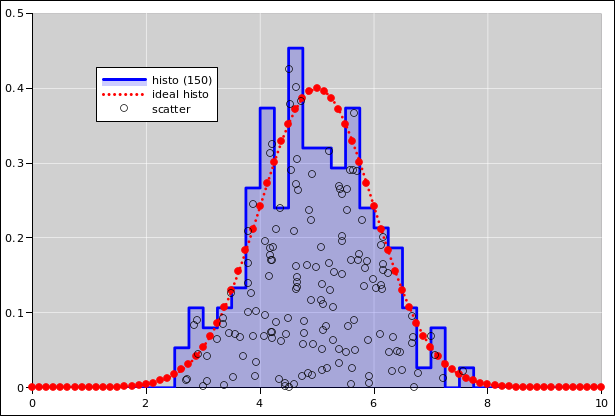
As for the probability-density histogram:
The support of each bin is a half-open interval of the form [L, R) such that the bin contains all events such that x is greater than or equal to L and strictly less than R. For continuous data, the chance that any data point falls exactly on a bin boundary is zero, but for discrete data this can become an issue, hence the careful definition of the bin-boundaries.
If the bin-width gets too small and there are not enough data points, the histogram becomes noisy. At some point a noisy histogram becomes hard to interpret; among other things, the idea of half-width at half-maximum becomes useless.
The spreadsheet function combin(n, k) returns the binomial coefficient “n choose k”. For example:
| (6) |
| (7) |
Here is a statement that produces a random integer according to a binomial distribution. In this example, there are 60 trials. (The number of trials is built into the statement.) The first argument to the binomdist function is the outcome. Here we use an array expression, using the range-of-numbers idiom mentioned in section 1.8. The second argument is the number of trials. The third argument is the probability of success per trial, which we assume is stored in cell $D$3. We use the sum function to count how many times the probability of a given outcome was less than the threshold, where the threshold is some random number stored in cell G7.
=sum(if(binomdist(row($A$1:$A$61)-1,60,$D$3,1)<G7,1,0))
Suppose we use that formula 200 times, using a different random threshold each time. The results are shown in the following figures. See reference 8 for details.
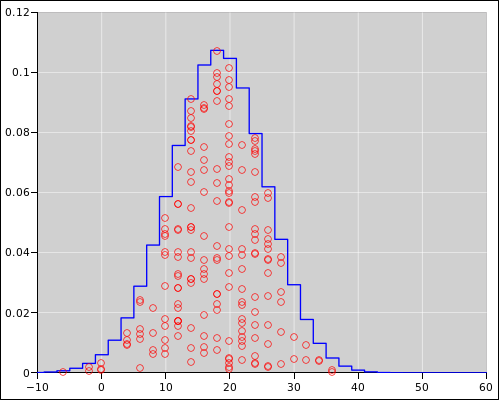
|
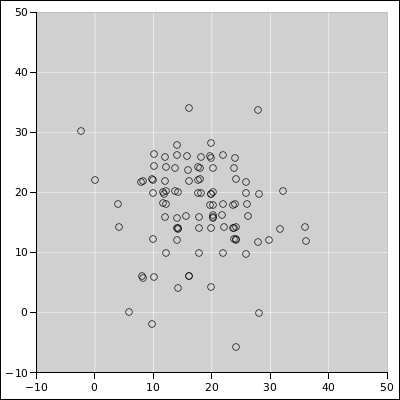
| |
| Figure 20: Binomial Distribution : Diaspogram | Figure 21: Binomial Distribution : XY Scatter Plot | |