Security Recommendations for Any Device
that Depends on Randomly-Generated Numbers
John Denker
* Contents
1 Emergency Operation
1.1 Big Hurry
Suppose you are setting up a brand-new system. Let’s call it the Red
machine. Imagine booting from a so-called “Live Distro” on a thumb
drive or CD. There is a nontrivial risk that the new system will not
have a sufficient endowment of good-quality randomness. This is a
problem, because all modern data-security methods depend utterly on
having access to a good randomly-distributed numbers.
You seriously need to install a random seed before doing any
serious work on the Red machine, in particular before generating any
cryptologic keys, and before setting up any network connections that
need to be secure.
If you are stuck somewhere without turbid or other fancy tools, and
you need some hard randomness right away, here are some things you
might try:
1.1.1 Sneakernet
Go to a machine you trust (call it the Blue machine) and grab some
random bytes from /dev/urandom. Copy them to a file on the thumb
drive, and hand-carry it to the Red machine.
: blue; dd if=/dev/urandom of=/thumb/random.seed bs=512 count=2
On the Red machine, copy the bits into /dev/urandom.
: red; cat /path/to/random.seed > /dev/urandom
Thereafter you can use /dev/urandom to supply the randomness this
machine needs.
This should be very little extra work, because you probably needed to
bring over some other stuff anyway, such as personal keys.
If you are booting from a thumb drive, you can partition it so that
the operating system is in the first partition, and your personal
files (and random seed) are in some other partition.
1.1.2 Audio Input : Johnson Noise
Here’s how you can generate a high-quality random distribution on the
spot, without relying on any other computer:
Open-circuit the mic input on the computer. On a desktop this
is trivial. On a laptop with a built-in microphone, this means
finding a piece of wood or plastic with a diameter between 3.0 and 3.3
mm, then sticking it into the mic jack.
- Example: My local hardware store sells 1/8” diameter hardwood
rods, 36” long, for 59 cents. That’s enough to make open-circuit
plugs for dozens of laptops, as shown in figure 1. Suggestion: Cut a 1” long piece of dowel
rod and tape it to the laptop somewhere, so you will always have it
with you. (My laptop has a recess on the bottom that is ideal for
this.) Don’t leave it plugged in when not in use, especially when
traveling, lest it get smashed.
- Example: If you have some plain 1/8th inch audio plugs, that
is a fine way to open-circuit the mic jack. If you don’t have any,
you should get a couple, because you will need them for doing a
proper calibration, as soon as the emergency is over.
- Example: You can plug in an audio extension cable and leave
the far end disconnected. This is not quite ideal, but it works.
- If you don’t have any of the items mentioned above, and are in
such a hurry that you you don’t have time to go to the store, you
can improvise. For example:
- On one occasion I used the ink tube from inside a cheap
Bic “Ultra” ball-point pen.
- On another occasion I used a disposable bamboo chopstick.
Whittling it to the right diameter took about a minute.
- On another occasion I used the insulation stripped from a
a scrap of 12-gauge solid copper wire.
Use alsamixer to turn all the gains all the way up. Then
record the electrical noise coming from the audio front-end
components:
:; arecord -D hw:0 --disable-softvol -f S32_LE -r 44100 -V mono -d 3 noise.wav
:; aplay noise.wav
:; cat noise.wav > /dev/urandom
Play back the file, and listen to it using speakers or headphones. If
it doesn’t sound like white noise, try again until it does. Then
stuff the file into /dev/urandom. You can use the .wav file
as-is; there is no need to reformat the data.
If the machine doesn’t have audio circuits at all, for a few dollars
you can buy a USB audio dongle and use that.
If you have a decent A/D converter, it should have a bandwidth on the
order of 18kHz or more, and should provide several bits of randomness
per sample ... provided the mic input is actually open-circuited
and the gains are turned all the way up. If we degrade that to 1 kHz
and 1 bit per sample, the noise.wav file should still contain
3000 bits of hard randomness, which should be plenty enough for
initializing a cryptologically-strong PRNG.
Then use the PRNG (i.e. /dev/urandom) to generate as many random
samples as you like.
There are a lot of things that could go wrong with this, some of which
are discussed in section 1.3, but in an emergency, this
gives you a way to generate some high-quality randomness ab
initio, and is much more reliable than most of the other options.
1.2 Some Platforms Cannot Be Made Secure
It must be emphasized that some platforms are not secure and cannot be
made secure. You almost certainly need a PRNG (/dev/urandom or
otherwise), and any PRNG needs to be seeded. It is often impossible,
or very difficult, to tell whether this has been done properly.
You can force the issue by seeding the PRNG yourself, but bear in mind
that the system may already have been compromised, long before you got
around to doing this.
In particular, suppose you are administering a remote machine, so that
you don’t have access to the USB ports or the audio ports. It is
entirely possible that there is no good way to install sufficient
randomness. You need to prevail upon whoever has access to the remote
machine and get them to provide something, perhaps a random seed file,
or a virtual /dev/hwrng, or a real hardware-based solution (using the
audio system or otherwise). If they can’t or won’t do that, you can
plan on being hacked.
|
Failure is Always an Option.
|
|
|
|
Security requires attention to detail. It doesn’t do much good to
triple-lock the front door while the side door and the windows are
standing open.
1.3 Looking Slightly More Closely
Consider the contrast:
|
If at all possible, you should validate the randomness of the
data from which you derive your random seeds.
|
|
Proper validation is
very much harder than it seems. In this section, we discuss an
approach that seems tempting, but is in fact heavily flawed, and
should be used only in emergencies.
|
We now discuss some rough checks can be performed using only
relatively prosaic tools, as folllows, for emergency use only:
:; arecord -D hw:0 --disable-softvol -f S32_LE -r 44100 \
-V mono -d 3 -t raw noise.raw
:; aplay -f S32_LE -r 44100 -t raw noise.raw
:; <noise.raw od -t d4 -j400 -v -w4 -Anone -N8192 > noise.csv
:; gnumeric noise-graphs.gnumeric
:; gnumeric noise.csv # copy-and-paste into the other worksheet
Then you can use a spreadsheet app to look at the data. First look at
it as a function of time, as in figure 3.
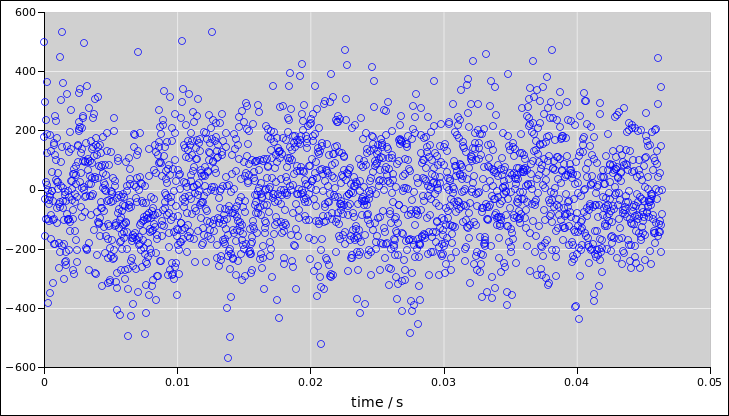 Figure 3
Figure 3: Noise Voltage as a Function of Time
Then take the Fourier transform and look at it as a function of
frequency, as in figure 4.
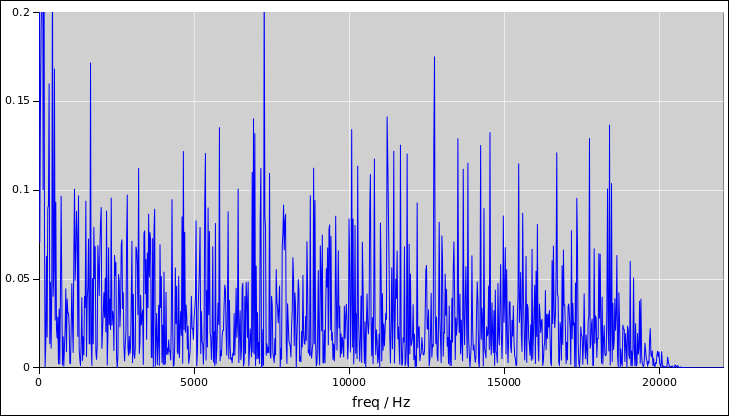 Figure 4
Figure 4: Noise Power as a Function of Frequency
The spreadsheet used to produce these figures is cited in reference 3.
Beware: It must be emphasized that you can never tell whether a
signal is random just by listenint to it or looking at it. Although
the data in figure 4 looks perfect random, it was in fact
generated by a PRNG with a known seed, and if I told you the seed you
could regenerate the data exactly, and predict all future samples from
the distribution.
That may seem like an extreme example, but similar problems can arise
naturally, producing seemingly-random signals that contain vastly less
randomness than you might have guessed.
The more we look into this, the more we discover that simple checks
can be very misleading. For example, the red signal (in figure 7) has at most 1 bit of randomness per sample. As
you can see, it’s a two-state system. This sort of problem can arise
naturally when the audio system digitizes the signal too coarsely.
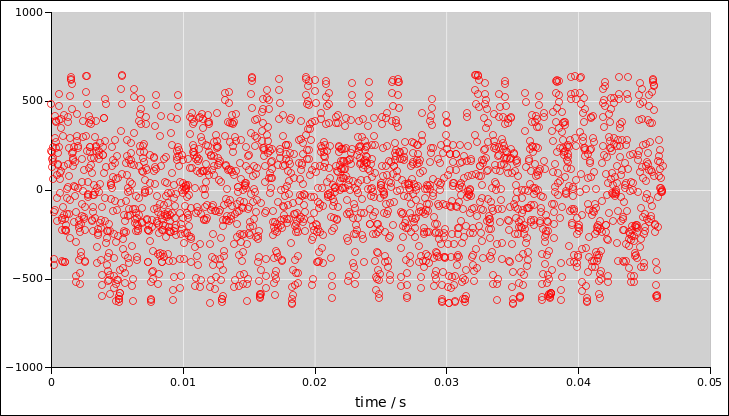 Figure 5
Figure 5: Noise Voltage as a Function of Time
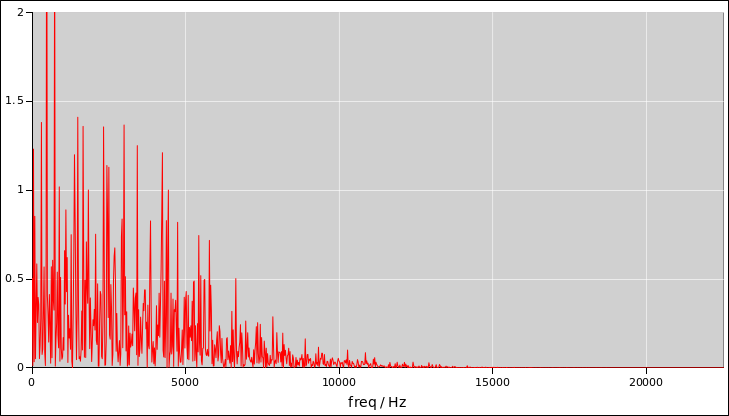 Figure 6
Figure 6: Noise Power as a Function of Frequency
Things are even worse in figure 7. It is a
low-pass filtered version version of the previous signal. The samples
are now correlated with one another, to a significant degree. The red
signal has an effective bandwidth of only about 6000 Hz, even though
the sample rate is the same as the blue signal, namely 44100 Hz. So
the red signal has much less total randomness.
You can’t determine any of this just by listening, because all three
signals sound more-or-less the same.
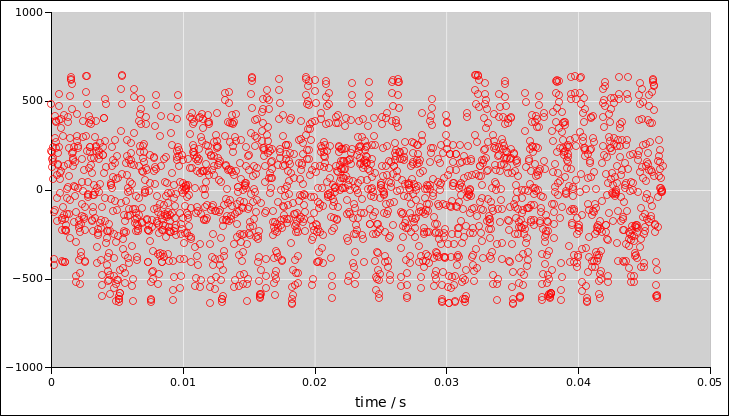 Figure 7
Figure 7: Coin Toss Voltage as a Function of Time
The Fourier transform will tell you the bandwidth, which is important,
but it won’t tell you much about the amount of randomness per sample,
which is also important.
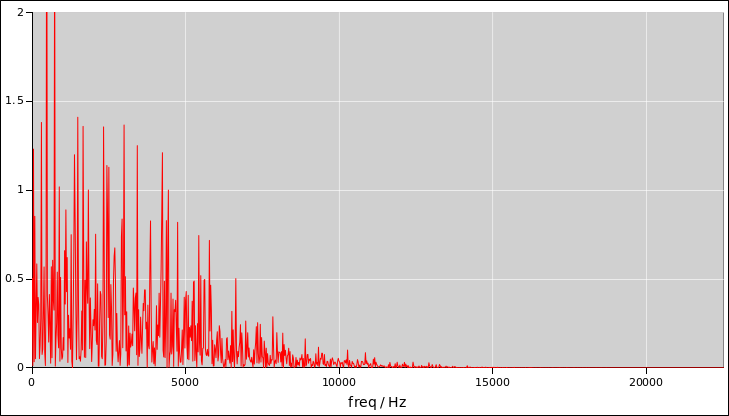 Figure 8
Figure 8: Coin Toss Power as a Function of Frequency
2 Overview
Randomly-generated numbers play a crucial role in many applications
including
-
data privacy and integrity
(e.g. for data communications and data storage)
- identification and authentication (e.g. passwords)
- Monte Carlo integration, simulated annealing, etc.
- Address space layout randomization
- gaming and gambling
- business and military strategy
- et cetera
History shows that any compromise of the random generator can have
disastrous implications. See reference 2 for a list of
historical examples, plus additional discussion.
Today there are a very wide range of devices that depend on
randomly-generated numbers:
-
the Internet of Things (IoT), i.e.
very small, unobtrusive, widely distributed devices;
- cell phones and PDAs
- large-scale routers and communication hubs
- very large servers
- virtual machines (VMs) running within larger hosts
Several of these pose special challenges, due to paucity of resources
(IoT, VM) and/or magnitude of demand.
It is quite challenging to construct a proper RNG. This is a job for
experts. There are a lot of untrustworthy RNGs in use today, which is
a problem, non-experts who try to fix the problem are likely to make
it worse, not better.
Note the contrast:
|
Loosely speaking, a PRNG is “mainly” based on
algorithms.
|
|
Loosely speaking, a HRNG is “mainly” based
on physics.
|
|
It is impossible in principle to have a PRNG without a HRNG.
That’s because every PRNG must be seeded. Where is the seed going to
come from? If you get it from some other PRNG, it reduces to the
problem previously not solved. The only real solution is to get
it from a HRNG.
|
|
It may be possible to imagine a HRNG that uses just
physics, without relying on any cryptographic algorithms, but I’ve
never seen it done. The problem is that practical physical sources
often provide high-quality randomness in a somewhat dilute form.
|
You can accomplish a lot more with physics and algorithms together
than you can with either one separately.
|
|
|
|
3 System Considerations
An operating system must provide a unified good RNG device, namely one
that has 100% availability along with 100% high quality, high
enough for any earthly purpose.
Rationale and other observations:
- If /dev/urandom or /dev/random blocks, applications (and
libraries such as openssl) will not rely on it. Instead they will
roll their own PRNG, with predictably terrible results.
- If /dev/random or /dev/urandom returns insufficiently
unpredictable bits, applications (and libraries) will use
it to produce insecure products.
- Other ways of expressing this principle include:
- Neither /dev/random nor /dev/urandom should be permitted to block.
- Neither /dev/random nor /dev/urandom should be permitted to emit
untrustworthy bits.
- When designing the “main” RNG that is offered to users,
if the designer ever needs to make the tradeoff, namely
blocking versus producing untrustworthy bits, the game is
already lost.
- If this requires storing some randomness so that it is available
super-early during the boot process, so be it. If this requires
mods to the kernel, grub, userland tools, and (!) hardware, so be
it.
- Minor additional point: It might be nice to assign a proper
name to the unified trustworthy device, perhaps /dev/jrandom
(as in J. Random Hacker) or /dev/vrandom (as in Very random,
also the lexical successor to urandom).
That serves as a way of advertising its features to applications
(and libraries). Then the advice is simple: If the good device
exists, use it. On systems where it exists, it can be aliased
as /dev/random and /dev/urandom et cetera, so that legacy
applications continue to work, and indeed work better than
before.
On systems where the good device does not exist, applications
are stuck with unanswerable questions about whether to use
/dev/random or /dev/urandom, neither of which reliably solves
the problem.
4 Pseudo-Random Generators
Most users should not care whether their “random” bits come from a
PRNG or from a HRNG, so long as the bits are sufficiently
random. This includes all non-experts, and most of the time it
includes experts, too.
For a wide range of applications, a high-quality PRNG (pseudo-random
generator) is the best solution. The PRNG has some internal “state”
variables, i.e. the seed. The seed must be properly initialized and
kept secret from all adversaries. Experts distinguish a PRNG from a
HRNG, but the distinction is not as sharp as you might imagine, as
discussed in section 9.
Here are some remarks that apply to PRNGs in general. Some special
cases will be discussed in later sections.
-
Every device must have its own seed. By device I mean
to include every computer, every phone, and everything else that
needs to process, store, or communicate data securely. This includes
every virtual-machine guest, in the sense that each instance of
the VM needs its own unique seed.
-
The stored seed must be random enough,
private enough, available early enough, and refreshed often enough.
For details on this, see section 6.1.
-
The stored seed must be provisioned before
the device is booted up for the first time.
Note that this should not be considered a radical proposal, because
every device, from the simplest to the most complex, already has a
provisioning process. A phone is provisioned with an IMEI. A
network interface is provisioned with a MAC address. A computer is
provisioned with a hostname and a password file. The point here is
that a seed for the PRNG must be included on the list of things
that must be provisioned, on a per-instance basis. Here are some
important sub-cases:
- Every hardware manufacturer must take responsibility for
provisioning a proper seed in each device, at the time of
manufacture.
- Every virtual-machine host must take responsibility for
provisioning a proper seed for each VM guest, unique to each
instance. (Preferably, the host should also provide each guest
with an ongoing supply of hard randomness. This can be done
in various ways, perhaps a via a virtual /dev/hwrng or
otherwise.)
Special considerations apply when booting from read-only media.
See section 6.5 and section 6.6.
-
Provisioning/seeding the PRNG is in some ways
similar but in some ways different from provisioning/seeding a
buffered HRNG; see section 9.3.
-
The stored seed should never be re-used, except in
emergencies. Any such emergencies must be handled with great care,
as discussed item 9.
-
To prevent re-use, the seed-file should be
rewritten early and often.
- The seed should be rewritten with a new value at the first
opportunity, as part of the system startup process, to protect
the old value from prying eyes.
- The seed-file should be rewritten from time to time, even if
it has not been used. This is to limit the amount of damage that
would be done if an attacker gets temporary read-access and steals
a copy of the seed file ... whether from the running system or from
a backup image or whatever.
- The seed-file should be rewritten during the
system shutdown process, if possible, to protect the
new value from prying eyes.
However, beware that you cannot depend on the device to carry out
an orderly shutdown. There are plenty of devices in this world
that never carry out an orderly shutdown. That is, they stay
up until they crash. Therefore it is strongly recommended that the
seed-file be rewritten at the first opportunity, and rewritten
every so often thereafter, as part of normal operations.
- The seed file should never be zeroed, but should instead be
overwritten with a new random value.
To repeat: The seed-file should be rewritten at the first
opportunity, and at the last opportunity (if possible),
and from time to time in between.
-
The seed must be stored in some form of
non-volatile read-write memory. The memory needs to persist across
reboots, crashes, and power failures. It needs to persist even if
the system crashes without going through an orderly shutdown
sequence.
-
The seed must be kept secret. The file permissions
should be set to allow reading by only the most privileged users.
The file should be excluded from the normal backup process. If the
machine needs to be restored from backups, the seed should be
regenerated ab initio.
-
At boot-up, the seed should be stirred using a
high-resolution value from the Real-Time Clock (RTC). This is to
defend against the scenario where the device is rebooted after a
short time, before it has a chance to rewrite the seed file. This
counts as an emergency, insofar as the the seed-file is being reused.
It should not be imagined that the RTC by itself is sufficient to
initialze the PRNG. That’s because every attacker in the world knows
what time it is. Similarly, it should not be imagined it helps to
mix in MAC addresses, serial numbers, or other things that might be
known or guessable by the attacker. Furthermore, it should not be
imagined that stirring in the RTC is an acceptable long-term
substitute for reseeding the PRNG. However, combining the RTC with
the seed that is available early enough, random enough, and unknown
to the attacker should be sufficient for dealing with this specific,
short-term emergency situation. It also has the advantage of being
easy to implement.
-
The stored seed must be loaded into the PRNG very,
very early during the boot process, before any signifcant demands are
placed on the PRNG.
At present, this is what we call an “opportunity for improvement”
because the currently-distributed system software loads the seed-file
far too late, as discussed in section 5.
-
The PRNG must be re-seeded every so often during normal
use. This is to limit the damage that would result from a
compromise. If this is done properly, it deters the adversary from
even attempting the attack. The new seed material should come from a
True Random Number Generator (TRNG) such as a Hardware Random Number
Generator (HRNG).
If the machine does not have a TRNG on board, the seed material can be
obtained from a remote TRNG, via a secure network connection. This
underlines the importance of having a proper stored seed, because
without that, it would be impossible to set up a secure connection,
and there would be a chicken-and-egg problem.
In a VM situation, it would be nice for the host machine to provide
randomly-distributed numbers to its guests. Obviously a virtual
machine cannot have its own TRNG on board, unless the host provides a
virtual TRNG, via the VIRTIO-RNG interface or some such. The virtual
TRNG is not absolutely necessary, but it is usually more efficient,
more flexible, and more reliable than fetching randomly-distributed
numbers over a network connection.
Note that you should not go overboard worrying about a possible
compromise of the PRNG. If the attackers can read the state of the
PRNG, they can probably read your passphrases and private keys
directly, so you have already lost the game, and re-seeding the PRNG
won’t help.
-
Again: Special considerations apply in situations
where the device is booted from read-only media. See section 6.5 and section 6.6.
5 Discussion
A modern operating system uses random numbers for a wide variety of
purposes. Some of these numbers are needed very early in the startup
process, for example in connection with address space layout
randomization (ASLR).
As of late 2013, the typical widely-used Linux distributions have a
stored seed file, and rely on an “init script” to load it into the
kernel. This is a problem, because the kernel makes heavy use of the
RNG system before it is initialized. Here are some observed
numbers illustrating the magnitude of the problem:
| | | prior |
| startup script | | #bits |
|
| | |
| (mountall) | | 18816 |
| (mounted-run) | | 21888 |
| (sshd server) | | 35616 |
| (network-interface : lo) | | 55968 |
| (network-interface : eth0) | | 68832 |
| (urandom) | | 79168 |
These are “typical” numbers for Ubuntu distribution 13.04 (“raring”)
as discussed below.
In the left column, we have the description of a startup script, as
observed on an ordinary Linux system. In the rightmost column we have
the number of bits extracted from the kernel PRNG before said script
gets invoked. The upstart process is asynchronous, for good reason.
As a consequence, the numbers tabulated above will exhibit some
variation.
The script that claims to be in charge of initializing the kernel PRNG
is getting called late in the game. This is definitely a problem.
As discussed in section 7, the proposal to use DHCP to seed the
PRNG doesn’t fix the problem.
I wrote some
code to translate the old sysv init.d/urandom to upstart. This
produces a different sequence:
| (urandom init) [startup] | | 18464 |
| (mountall) [startup] | | 19360 |
| (mounted-run) [mounted] | | 22560 |
| (urandom-save) [filesystem] | | 36800 |
| (ssh [server]) [urandom filesystem] | | 36800 |
| (network-interface : lo) [net-device-added] | | 63616 |
| (network-interface : eth0) [net-device-added] | | 67520 |
This is dramatically better, but still nowhere good enough. Many
thousands of bits have been extracted from the PRNG before the seed
file is loaded.
As discussed in section 7, the proposal to use DHCP to seed the
PRNG still doesn’t fix the problem.
6 Using and Refreshing a Stored Seed
6.1 Using versus Refreshing; Time Pressure etc.
As mentioned in item 2, the stored seed must be
-
random enough,
- private enough,
- available early enough, and
- refreshed often enough
These requirements must all be met, but they need not all be met in
the same way. In particular, the task of initializing the PRNG is
under severe time pressure, whereas the task of refreshing the stored
seed is normally under much less time pressure. Therefore one should
not be surprised to find these two tasks handled by different
mechanisms. Specifically, refreshing the seed could be handled by a
userspace utility.
On some software setups, the seed might be hidden deep inside a kernel
boot image or deep inside an initial ramdisk image. On some hardware,
writing to persistent storage might be very intricate and expensive.
It still has to be done, but it might be nowhere near as simple as
just opening a file.
6.2 Early Seeding is Good
Sometimes the question arises, what should the PRNG do if somebody
tries to use it before it is initialized? Should it block? Here’s a
suggestion:
|
Make sure the kernel PRNG is initialized very, very early.
|
-
Then the question of whether or not to block does not arise.
- Then the users have no temptation to evade the block.
In more detail: As of late 2013, the most widely-used /dev/random
implementation can easily lead to insidious failure, i.e. an
insufficiently-random distribution of bits. This is a problem. This
is a Bad Thing. The main goal should be to fix the problem ... and to
fix it such a way that it stays fixed.
Some applications cannot afford to wait. For these applications, if
the PRNG blocks, we have converted an insidious failure into a
manifest failure. It could be argued that this is a step in the right
direction ... but it is only a small step, and it does not
really fix the problem. It could be argued in political terms that
this would make users so angry that they would demand a real fix, but
creating demand for a fix without actually providing a fix is bad
politics, bad marketing, and bad engineering.
So this brings us back to the main point: The main goal should
be to implement a PRNG that is up and running very, very early.
In engineering-management terms: this is in the critical path.
By way of contrast, blocking is not in the critical path, because
even if you implement blocking, you still need to fix the
problem.
If you encounter a situation where the PRNG
has not been properly initialized,
do not treat it as reason for the PRNG to block;
treat it as a reason to initialize the PRNG earlier.
|
6.3 Suggestion: Storing a Seed in the Boot Image
Here is a specific suggestion for how the problem could be
fixed.
|
Incorporate the stored seed into the kernel boot image
(zImage or bzImage).
|
That ensures that the PRNG is “born” ready to go,
just as a newborn dolphin knows how to swim,
and a newborn rattlesnake is already venomous.
I have looked into this a little bit. Although I don’t
yet understand all the details, it looks like there is a
straightforward path.
Actually there are two complementary requirements:
– the stored seed must be available very, very early
– it should not be unduly difficult to refresh the
stored seed from time to time.
Refer to reference 4 and reference 5 for a
simplified view of the structure of the boot image.
Actually things are somewhat more complicated than item
12 in reference 5 suggests. The actual lines
from the relevant x86 Makefile include:
VMLINUX_OBJS = $(obj)/vmlinux.lds $(obj)/head_$(BITS).o $(obj)/misc.o \
$(obj)/string.o $(obj)/cmdline.o $(obj)/early_serial_console.o \
$(obj)/piggy.o
...
$(obj)/vmlinux: $(VMLINUX_OBJS) FORCE
$(call if_changed,ld)
(and even that is a simplification). Unless I am missing something,
it should be No Big Deal to add $(obj)/urandom-seed.o to the list,
somewhere ahead of $(obj)/piggy.o.
Next step: It should be straightforward to write a tool
that efficiently updates the stored seed within the boot
image. Updating MUST occur during provisioning, before
the device gets booted for the first time ... and also
from time to time thereafter. Updating the boot image
isn’t be quite as simple as
dd of=/var/lib/urandom/random-seed
but neither is it rocket surgery. The cost is utterly
negligible compared to the cost of a security breach,
which is the relevant comparison.
There are some systems that checksum the boot image, to make sure it
has not been tampered with. Storing a seed in the boot image would
require teaching the checksum routine to skip the seed. This requires
some work, but it is entirely doable work.
I have considered a great many alternatives. This is the one that
gives the most bang for the buck.
If we do this, many otherwise-difficult challenges just melt away.
6.4 Special Case: Air-Gapped System
In some special cases, there might be a system that is separated from
all networks by an air gap. It is used only for the most ephemeral
purposes. It is never used to process, read, write, or communicate
any secure data.
Such a system does not need a secure RNG, so the advice
in section 6.5 and section 6.6
is not relevant.
6.5 Avoid Read-Only Media
In most cases, with rare exceptions as noted in section 6.4,
the best advice is this:
If you feel the urge to use
read-only media and nothing else,
lie down until the feeling goes away.
|
In the vast majority of cases, anything you could do with a “Live
Distro” (sometimes called a Live CD or Install CD) could be done more
using a USB flash drive instead of an actual CD or DVD. This is more
convenient and vastly more secure. You can still boot from a
read-only partition if you wish, while still having a read/write
partition for storing seeds, configuration data, and other stuff that
should persist from one boot to the next (but cannot be built into the
read-only image).
Even if you insist on having the main boot image on read-only media,
you can carry around something else, perhaps a thumb drive, carrying a
random seed file and other critical personalization information.
A “kiosk” situation or “library” situation is not a sufficient
excuse to use read-only media; see section 6.7.
6.6 Special Case: Read-Only Media
Please see section 6.4 and section 6.5. Then, if
you are absolutely, positively sure that the system must be booted
from read-only media and nothing else, this must be handled using
special procedures.
There will not be a one-size-fits-all solution for these “read-only”
devices. Here are some of the considerations that apply to certain
common and/or important cases.
- When booting from a “standard” live-CD image on a
read-only medium, extra care is needed.
- If there is a trusted, calibrated hardware RNG,
use that.
- If there is some way of replacing the CD with a
read-write medium, do that, as discussed in section 6.5.
- If there is some way of supplementing the read-only
medium with something else, something that can hold a stored
seed file and other personalization info, do that, as
discussed in section 6.5.
- Another possibility is to download the .iso image to an
ordinary read-write disk, unpack it, provision the seed-file, pack
things up again, and then write the properly-provisioned image to
CD. This requires some work, but not unbearably much work. I wrote
some software tools to help with this.
If you don’t make more than one copy of the properly-provisioned CD,
don’t use it too many times, and don’t let it fall into the hands of
an attacker, and if you teach the kernel to install the seed early
enough, then this approach should do the job.
- Failing that, if the machine is being booted
interactively, try to harvest some randomness from
the user. Be careful with this, because humans
are notoriously unreliable sources of randomness.
In particular, we could teach grub to instruct the user to
roll some dice and feed the results to grub, via the keyboard.
Then grub can pass that to the kernel. This is a way of
ensuring that the randomness is available very, very early in
the boot-up process.
- Since grub already knows how to read files, it would also
make sense to have grub read a random seed file and pass it to
the kernel. Again the point is to make it available very,
very early in the boot process. This is in addition to the
interactive command mentioned in the previous item. (People
are working on this.)
- Failing that, recognize that it might be impossible to
boot into a secure state. There will always be systems that
are so badly designed that they cannot be secured.
This must not be used as an argument for not securing all the
other systems in the world, the ones that can be secured.
Let’s be clear: Suppose we have something that boots from
read-only media – booting repeatedly, unattended, with no
HRNG, with no hypervisor, with no non-volatile memory, and yet
no air-gap. This must be declared an unsound design. There
will always be systems that are so badly designed that they
cannot be secured.
Almost every “read-only” system I’ve ever seen has some
non-volatile memory somewhere. So ... it boils down to
a configuration problem, i.e. teaching the system how
to store the required seed in the right place ... or how
to get the hypervisor to provide a seed, or whatever.
Suppose we update the system software, perhaps to implement the
suggestion in section 6.3, or other security upgrades to the
PRNG or whatever. Applying such an upgrade to a read-only system
should not cause the system to suddenly fail. The worst that will
happen is that some init script will try to refresh the seed and will
be unable to do so. This will leave the system insecure, i.e. just as
insecure as it already is!
Also, don’t forget what we said in section 6.4 and
section 6.5.
6.7 Kiosk Machines and Library Machines
Consider the case of a “kiosk” machine or a “library” machine.
The idea is that the machine is frequently rebooted, and for security
reasons users are not allowed to store anything that persists from one
reboot to the next.
This does not mean that the machine must be rebooted from
read-only media. It just means that no information created by
untrusted users is allowed to persist from one reboot to the next.
Rather than using read-only media, consider running a “host” system
that in turn boots a “guest” system in snapshot mode. The
guest system has all the convenience of a read/write filesystem,
together with the security of knowing that the image goes back to its
previous state on the next reboot. (The host provides the randomness
that the guest needs for seeding the PRNG and for other purposes.)
A further advantage is that the guest can be booted in non-snapshot
mode on special occasions, for instance to install high-priority
security-related software updates. That’s tough to do on read-only
media.
(This assumes the Bad Guys have not already pwned
the signing keys used to distribute updates,
but that’s a separate issue entirely.)
In this situation, as in any virtual-machine situation, the host
should provide the guest with a reasonable supply of randomness. That’s
because it is very difficult for VM guests to generate their own
randomness.
- One particularly simple, standard approach is for the host to
provide randomness to the guest via a virtual /dev/hwrng device.
- Another simple possibility is to mount an additional partition
containing the seed-file. This does not leak information from one
instance to the next, since it is created anew prior to each reboot.
As always, the guest machine needs to know where to find the
seed-file, and needs to load it into the PRNG very, very early in
the boot-up process.
- Hypothetically, the hypervisor could pass a seed via the kernel
boot cmdline. At the moment there is no support for this in the
Linux kernel, but it would be easy to add.
7 Other Approaches
We can contrast the stored-seed approach with some other approaches
that have been suggested:
- In general, it is not sufficient to initialize the PRNG from a
external web server, DHCP server, or anything like that. That’s
because network connections are likely to become available too late
in the boot-up process. As you can see from the numbers tabulated in
section 5, a lot of water has flowed under the bridge
before the network devices come up, and IMHO it would be a Bad Idea
to assume (or require) that nobody can do anything random until
this-or-that network device has come up, let alone completed the DHCP
process.
- The system might have a fixed address, or some
other reason for not doing DHCP at all.
- The network interface might be a USB dongle that gets
hotplugged long after the system has come up, if at all.
- etc. etc. etc.
It could be argued that it is “sometimes” OK for everybody to wait,
but that argument doesn’t cut it. The shoe is on the other foot.
Showing that a system is secure requires showing that it is
always secure.
Here’s an example: The SSH system needs to cut host keys the first
time it is used (if not sooner), and this requires high-quality
randomly-drawn bits. As you can see in the tables in section 5, the ssh server comes up early ... before the network
devices, and before the urandom script loads the seed file.
Requiring sshd to start later is not a real solution, either. For
one thing, this is just one example among many; there are many
processes consuming many thousands of bytes, and you can’t make them
all wait. Also note that it may necessary to do “ssh
root@localhost” in order to configure the network ... in which case
relying on network timing to seed the PRNG fails miserably.
This stands in contrast to the stored-seed approach, which has the
advantage that the seed can be made available very, very early in the
boot-up process ... if things are done properly.
- In general, it is not sufficient to initialize the seed from
things like the MAC address, IMEI, serial number, hostname, etc.,
for multiple reasons. For starters, those things are likely to be
known to the attacker, or too-easily guessable. Also, unlike the
RTC, these values are static.
Such things are pointless from a security point of view. They are
also mostly harmless, excepat insofar as they waste CPU time. You can
mix them in if you’ve got nothing better to do, but you cannot rely
on them to do any good.
- In general, it is not sufficient to rely on the timing of
external events as a source of randomness to seed the PRNG, for
multiple reasons. For starters, it may be possible for the adversary
to observe or even manipulate such events.
Secondly, it takes time to collect randomness from such sources, and
during the critical startup phase, there are heavy demands on the
PRNG and we cannot afford to wait.
You can mix such things in if you want, but you cannot rely on them
to do much good, especially during times of greatest need.
8 Linux devices
The behavior of linux /dev/random, /dev/urandom, and /dev/hwrng has
changed repeatedly over time. They must be considered moving targets
even at the present time.
We must carefuly distinguish between how things are and how they
should be. Here are my recommendations:
- The “main” RNG offered to users should be a unified,
trustworthy device, with 100% availability and 100% random
outputs, as discussed in section 3.
- /dev/urandom and /dev/random should be equivalent
aliases for the aforementioned trustworth device.
- /dev/hwrng is “supposed” to be a HRNG. See
section 8.3.
Any decent general-purpose RNG must depend on some stored randomness
and on a HRNG (for re-seeding).
For many years, due to bad design, there have been conflicting
requirements imposed on /dev/random and /dev/urandom, leading to
needless waste of randomness, needless waste of CPU cycles, and
endless confusion about what these devices are and how they should be
used.
8.1 /dev/urandom
There should be no excuse for /dev/urandom blocking, ever.
There should be no excuse for /dev/urandom doing anything
except returning high-quality hard-to-predict pseudo-randomly
distributed numbers.
This should be adequate for almost all “ordinary” uses.
Note that the for all internal-to-the-kernel purposes, the
linux kernel depends on the PRNG provided by /dev/urandom.
The problem is, due to bad design, bad implementation, and
bad operation, there are lots of scenarios where /dev/urandom
returns low-quality squish. This needs to get fixed, pronto.
Fixing it MUST NOT involve making it block. If there is a situation
where the PRNG has not yet been properly seeded, it is not a reason
to block; it is a reason to make sure the PRNG gets seeded earlier.
In particular, much more attention needs to be paid to the issue of
per-instance provisioning. Every piece of hardware and every
instance of a VM guest needs to be provisioned with a high quality
seed. This needs to be done before the PRNG is used for the first
time. Provisioning is part of why I can say that there should be no
excuse for /dev/urandom to block, not ever, not even the first time.
8.2 /dev/random
/dev/random should meet the exact same requirements as /dev/urandom.
It should never block. It should always return samples from a
high-quality random distribution, high enough for any earthly purpose.
8.3 /dev/hwrng
The real (non-virtual) Linux /dev/hwrng is documented to be a HRNG,
based on a built-in source of hard randomness, such as the native
RDRAND instruction.
It might block. It should be for wizards only, e.g. for re-seeding
the system PRNG, not for use by typical userspace applications or
libraries.
There is not a tight connection between /dev/hwrng and /dev/random.
According to Documentation/hw_random.txt, if you want to
establish a connection, you should run a userspace daemon to transfer
bits from /dev/hwrng to /dev/random.
Things get even more complicated in a virtual machine. The virtual
/dev/hwrng is utterly reliant on the host. The host could feed bits
to the virtual device from the host’s /dev/random, /dev/urandom,
/dev/zero, or /usr/dict/words. The semantics is open to negotiation
between host and guest.
9 Hardware Random Generators
9.1 HRNG Overview
|
Hard randomness is not the only tool in the toolbox.
|
|
It remains, however, an essential tool.
|
|
Hard randomness is not by itself the figure of merit for
a good RNG. For many purposes, a well-seeded computationally-strong
PRNG is the right answer, even though the output of such a thing has
a near-zero density of hard randomness.
|
|
Hard randomness is
sometimes necessary, e.g. for seeding PRNGs. Unadulterated hard
randomnes is sometimes a good way to solve important problems,
e.g. high-stakes lottery drawings.
|
See reference 1 for a discussion of how to construct and
operate a high-quality hardware random generator. See
reference 2 for a discussion of the principles involved.
9.2 Stateless HRNG
Note that an ideal HRNG is stateless (or nearly so). The advantage is
that it requires no initialization, and recovers instantly (or nearly
so from compromise.
The disadvantage is that a stateless HRNG may produce randomness at only
a modest rate. It may therefore be unsuited to meeting a sudden spike
in demand. This is a nontrivial issue, since in practice the demand
is quite spiky.
9.3 Buffered HRNG
One can always buffer the output of a stateless HRNG, thereby creating
a buffered HRNG. The advantage is that the buffer can handle a sudden
spike in demand.
The disadvantage is that the system is no longer stateless. The
buffer counts as state. The bigger the buffer, the longer it takes to
recover from compromise. On the other hand, RNG designers should not
go overboard worrying about compromise. By the time the RNG gets
compromised, it is likely that the overall system is hopelessly
compromised in other ways.
It is sometimes helpful to store some randomness in a file, and use that
to initialze the buffer in the buffered HRNG. This improves the
response to peak demand in the early going, soon after startup. This
creates a potential vulnerability, if the file gets compromised, but
this is no worse than other vulnerabilities that are routinely
tolerated.
Keep in mind that initializing the buffered HRNG is conceptually
different from initializing a PRNG.
Note the contrast:
|
If you initialize the buffered HRNG, you can use that to
initialize the PRNG.
|
|
You cannot possibly use the PRNG to initialize
the HRNG.
|
|
The HRNG initialization file must contain hard randomness.
|
|
The PRNG initialization file generally contains pseudo randomness.
|
|
Current Linux distributions make no attempt to store hard
randomness or to initialize the /dev/random buffer. It would not be
particularly tricky to do this, but it is not done at present.
|
|
The
Linux kernel PRNG (/dev/urandom) is seeded from a stored file, as
discussed in section 5. The stored seed is pseudorandomly
generated, and the kernel correctly attributes zero “credit” to it.
|
9.4 Keep Them Separate
The buffered HRNG should be separate from the unbuffered HRNG. They
should have separate interfaces, so that users who demand instant
recovery from compromise can have it, and those who demand high peak
output can have it.
Trying to combine the two is a lose/lose proposition. It degrades
both, quite unnecessarily. This is a very common mistake, but that
doesn’t make it any less of a mistake.
9.5 Calibration is Required
There is no algorithm that can generate randomness. Therefore any HRNG
depends on input from some hardware device. It is necessary to
calibrate the input device. For example, the randomness available
from a soundcard depends on the input impedance, gain, bandwidth, and
temperature. Calibration is not easy. It requires skill in a number
of areas, including physics, electrical engineering, programming, and
cryptography. However, just because it is hard is no excuse for
skipping this step.
There are some people running around who think they can make a silk
purse out of a sow’s ear, if only they can get their hands on
“enough” sow’s ears. This is nothing but wishful thinking. It will
never result in a secure system. An ounce of calibration is worth
more than a ton of wishful thinking. An ounce of real hard randomess
is worth more than a ton of squish.
When calibrating a source, perfect exactitude is not required. It is
OK to err on the side of underestimating the randomness content. It is
not OK to err in the other direction.
9.6 Combining Multiple Sources, or Not
If you think it is necessary to combine multiple sources, we can
discuss it. The discussion would have to start with why you think it
is necessary. Multiplicity is not a goal unto itself.
10 Appendix: Multiplicity versus Reliability
Regarding the distinction between multiplicity and reliability:
There are some colorful proverbs concerning multi-engine versus
single-engine aircraft:
- You’d rather have an overpowered single than an underpowered twin.
- You’d rather have a reliable single than an unreliable twin.
- The second engine doubles your chance of engine failure. Its main
purpose is to fly you to the scene of the accident.
These maxims are colorful, but not exactly humorous, since we are
talking about matters of life and death. There are really strong
statistics to support what I’m saying.
My favorite proverb of all is the one that says for every proverb,
there is an equal and opposite proverb. In this case, we should note
that the proverb about not putting all your eggs in one basket is
not necessarily a sound engineering principle. The right answer
depends on the margin of error and on the per-basket failure rate. It
also greatly depends on the chance of correlated, uncorrelated, and
anti-correlated basket failures. Sometimes the best strategy is to
put all your eggs in one place and then guard that place carefully.
Birds have been following this strategy for 50 million years.
Of course having more sources is better than having fewer, other
things being equal. The problem is that other things are almost never
equal. We need to distinguish ≥ (better than) versus ≫ (much
better than.
|
| | 4 good sources |
| ≥ 3 good sources |
| ≥ 2 good sources |
| ≥ 1 good source |
| ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫ |
| ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫ |
| ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫ ≫
4 | lousy sources |
| | ≥ 3 lousy sources |
| | ≥ 2 lousy sources |
| | ≥ 1 lousy source |
|
(1) |
It may be that 4 lousy sources is better than 1 lousy source, but it
is not enough better to make up for the difference between any
number of lousy sources and any number of good sources.
11 Appendix: Random Numbers, or Not
There is no such thing as a random number.
- If it’s random, it’s not a number.
If it’s a number, it’s not random. - You can have a random distribution over numbers, in which
case the randomness is in the distribution, not in any particular
number that might have been drawn from some such distribution. A
distribution is different from a number as surely as a
high-dimensional vector is different from a scalar.
- The phrase “random number generator” should be parsed as
follows: It is a random generator of numbers. It is not a generator
of random numbers.
12 References
-
-
John Denker,
“Turbid RNG User Manual”
https://www.av8n.com/turbid/paper/turbid.htm
-
John Denker,
“Random Number Generators”
https://www.av8n.com/turbid/paper/rng-intro.htm
-
John Denker,
“Spreadsheet to Plot Noise Time Series and Spectra”
../noise-graphs.xls
../noise-graphs.gnumeric
-
Wikipedia article, “Vmlinux”
https://en.wikipedia.org/wiki/Vmlinux
-
FAQ: “Boot Image”
https://www.faqs.org/docs/kernel_2_4/lki-1.html
-
Kernel source: include/linux/moduleparam.h
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/moduleparam.h
-
Kernel source: arch/x86/kernel/setup.c
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/arch/x86/kernel/setup.c
-
Kernel source: init/main.c
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/init/main.c
-
Kernel source: kernel/params.c
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/params.c

