Figure~1: Two-Pan Equal-Arm Balance
Introductory Discussion |
Here is a rough statement of the puzzle:
It pays to analyze the problem in a systematic way. Here are some hints to help you get started.
Remark: Note the following contrast:
| You may have heard it said that when designing experiments, you should never change more than one variable at a time. As discussed in reference~1, that’s reasonable advice in situations where experiments are cheap and thinking about the results is the hard part. | On the other hand, in the real world there are lots of situations where the experiments are very expensive, in which case it pays to minimize the number of experiments and maximize the information you get from each experiment. In this case, you almost always wind up changing more than one variable at a time. You have to be clever about how you analyze the results of each experiment. Sometimes cleverness pays off. |
More Advanced Analysis |
Let’s start over. Let’s analyze the same problem, plus several variants of the problem, using some more sophisticated techniques.
Version 1a: You are given twelve coins. All appear to be identical, as far as you can tell by eye, but you are told that one of them is a counterfeit. All genuine coins have the same mass, while a counterfeit is either lighter or heavier than a genuine coin.
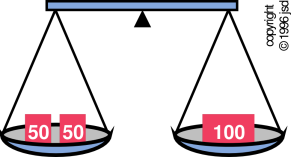
You are allowed to weigh coins using a two-pan equal-arm balance (sometimes called a scale or scales), as shown in figure~1. The balance provides one of three possible indications: the right pan is heavier, or the pans are in balance, or the left pan is heavier. The balance has sensitivity sufficient for the task. Note that the result is qualitative not quantitative: there is no indication of how much heavier the heavy pan is.
Your mission, should you decide to accept it, is to identify the counterfeit coin and tell whether it is “light” or “heavy”, using at most three weighings.
You are not allowed to tamper with or scrutinize the coins, nor gather any information about them except by the three weighings. You may, if you wish, label the coins if that helps you keep track of which is which.
Version 2a: Same as version 1a, but you are told that at most one of the coins is a counterfeit, i.e. possibly all 12 are genuine.
Version 1b: Same as version 1a, with the added restriction that we want a parallel algorithm. That is, you must decide in advance (before any weighings are carried out) which coins are to be weighed in each of the three weighings. Most people are tempted to use the results of the first weighing to help design the subsequent weighings, but that is disallowed in this version.
Having a parallel algorithm means, among other things, that the three weighings can be performed in any order.
Version 2b: Same as version 2a, with a parallel algorithm.
Extended versions: There are four more versions x1a through x2b, the same as the above, except that there are thirteen unknown coins, and you are allowed to supply one known-good coin of your own and use it in the weighings however you like.
Beginners are encouraged to start with version 1a, which is the easiest. In this note we will solve version 2a and immediately extend it to version x2b, which is the hardest version. All the other versions are then seen as corollaries.
This is an example of what scientists call a “Design of Experiment” (DoE) question. Entire books have been written about DoE.
Let’s start by reconnoitering the situation using the methods of information theory. For a nice, accessible introduction to information theory, see reference~2.
The first step is to calculate the entropy,2 i.e. how much we don’t know about the problem. In version 1, there are 24 possible outcomes:3 perhaps coin #1 is heavy, perhaps coin #2 is heavy, and so forth for twelve possibilities, plus another twelve possibilities if the counterfeit coin is light. Invoking the minimax4 principle, we assume that these 24 outcomes are equally likely. That gives us a total entropy of
| ~~~~~~~~~~~~~(1) |
We get to compare this with the information we hope to get. The balance provides only three possible results per weighing. If we are lucky, we might hope that the results are equally likely, or nearly so, in which case each weighing gives us one trit of information. If the results are not equally likely, the information will be less. Therefore we have the following upper bound on the amount of information available:
| ~~~~~~~~~~~~~(2) |
The upper bound is high enough, but there is not much to spare. We need an approach that is very nearly optimal.
As an example of bad design, consider for a moment what happens if the first weighing involves three coins in the left pan, three coins in the right pan, and six bystanders. There is a distinct possibility that the pans will balance. That tells us that the counterfeit is among the six bystanders. So we are left with a reduced version of the original problem: six coins with two weighings remaining. Information theory tells us that this reduced problem is, alas, provably impossible. There are twelve possible outcomes (which coin, light or heavy) but there are only nine possible results of the remaining weighings. That is, we have 2.26 trits of entropy remaining but at most 2 trits of information available. This is a hopeless situation.
As an example of much better design, consider what happens if the first weighing involves four coins in each pan plus four bystanders. This has the nice property that the three possible outcomes (left heavy, balance, right heavy) are equiprobable, so the first weighing returns the maximum possible information, i.e. one full trit.
Suppose the pans balance. We are left with a reduced version of the problem: four coins with two weighings remaining. This problem is not hopeless: we have eight possible outcomes (1.89 trits of entropy) and we have a reasonable hope of getting sufficient information from the remaining weighings.
Now suppose the pans don’t balance. This leaves us with eight coins and two weighings remaining. However, there are only eight possible outcomes (not sixteen), since once we identify which of the eight coins is the counterfeit, we know (based on the results of the first measurement) whether it is heavy or light. So once again we have eight possible outcomes (1.89 trits of entropy) with two weighings remaining, so there is hope.
Additional examples of this sort of hypothesis testing can be found in reference~3, reference~4, and reference~5.
Let’s treat the balance as a sort of communication channel. That is, suppose it is trying to transmit to you a code telling you the answer to the puzzle. The channel has an alphabet with only three symbols (L, B, and R) denoting respectively left-pan heavy, balance, and right-pan heavy. The channel can give you only a single codeword consisting of three such symbols. So the overall task reduces to this: using some subset of the 27 possible codewords, we want to assign a codeword to each coin. The codeword must be unique to that coin, and the set of codewords must obey certain constraints as discussed below.
First, let’s just look at all 27 codewords. It is easy to construct this table; it’s just counting in base 3.
| ~~~~~~~~~~~~~(3) |
Now, suppose you pick one of the codewords such as RRB and paint it on one of the coins. You can think of the codeword in two ways:
At this point the alert reader will be wondering what happens if the coin we marked RRB is lighter than a genuine coin. Then the balance will report LLB, that is, left-pan heavy, left-pan heavy, neutral balance. From this we conclude that if we have marked one of the coins RRB, we must not mark any of the other coins LLB, lest there be ambiguity. More generally, every time we use a codeword from the list in equation~3, we must “burn” its inverse code. (The inverse is formed by replacing L with R and vice versa.)
Consequently, even though it appears we have 27 codewords, this approach has no chance of handling more than 13 coins. Since we are only required to handle 12 coins, things are still on track.
There is one other constraint: The balance is only capable handling an equal number of coins in the two pans. So we must choose a set of codewords (a subset of equation~3) with the property that in each of the three columns the number of Rs equals the number of Ls.
The design process proceeds as follows: We immediately discard the BBB code as being unsuitable for marking on any coin ... since a coin that participates in none of the weighings can never be properly characterized.5 Now take the top half of equation~3, i.e. codes 1 through 13 as a tentative set of codewords. We get to discard one, because we only need 12. The obvious choice is to discard the RRR code, because by doing so we create an even number of Rs and Ls in the remaining set. Finally, we replace four of the codes by their inverses. (Remember, we get to use any given code or its inverse.) We need to do some inverting because the tentative set started out too rich in Rs in the first column, and we need to turn four of them into Ls. To make a long story short, it suffices to invert 12, 11, 9, and 7. The result is:
| ~~~~~~~~~~~~~(4) |
If you scrutinize equation~4, you will discover the following nice properties:
The codewords in equation~4 solve version 1 of the problem directly. They also solve version 2, if we adjoin the observation that if the balance generates the BBB codeword it means no counterfeit is present.
To solve the extended versions of the puzzle, adjoin the RRR codeword to equation~4 and put the known-good coin in the left pan.
In the language of Design of Experiment, these twelve codewords are the test vectors.
If you are good at visualizing things in higher dimensions (most people aren’t) it may be amusing to visualize these test vectors as shown in figure~2.
If you scrutinize the figure, you can discover quite a number of interesting properties.